SLC Use Cases for Access to Databricks
Randy Betancourt, May 13, 2025
Summary
The purpose of these use cases is to illustrate Altair SLC integration techniques with Databricks. SLC is a data analytics environment that includes a SAS language compiler. SLC offers a single, integrated environment to execute SAS language, Python, R, and SQL programs through a single IDE.
Databricks is a popular cloud-based data platform consisting of numerous sub-components. Databricks offers a convenient encapsulation for deploying an Apache Spark cluster and executing PySpark programs. It also provides a relational model (SQL) for accessing data assets.
Large organizations want to continue to utilize their existing stock of SAS language programs and to integrate these programs with workflows involving Databricks. These integration requirements go beyond bi-directional data interchange between SLC and Databricks and can include remote PySpark code execution and data exchange at the block-storage level.
Given the growing use of languages such as Python and R, we also illustrate SLC’s ability to read and write data formats such as Parquet and Apache Arrow. These data formats can provide a common data interchange between Python/PySpark and R along with SLC. These data formats along with others may form the granular data used as inputs into ETL pipelines for data refinement.
Use Case Patterns
We have chosen three common SAS language patterns for these use cases. They are:
- SAS language examples where SLC and Databricks exchange data using the Databricks LIBNAME engine. This pattern is popular since it provides an abstraction in the form of the familiar relational table model common between permanent SAS datasets and tables managed by Databricks. SLC supports both implicit and explicit SQL pass-through. This makes it possible for SAS language users to use non-SQL language elements, that is, Data Step statements to meet their processing needs. It also means SLC implicitly hands-off processing such as projection, selection, summarization and sorting to Databricks for in-database processing where suitable.
- SAS language examples calling REST APIs though PROC HTTP. This method is useful in cases where access to data inputs is exposed through a public API for read/write/update access. In addition, PROC HTTP can be used to extend SAS language programs responsible for ETL processing by using HTTP verbs POST (write) and PUT (update) to upload JSON, XML, or even CSV payloads to server-based resources.
- Access to remote compute resources with in-line calls to SLC’s PROC PYTHON and the import of client-side libraries provide program control to remote resources within a Databricks environment. These libraries provide low-level services which can be used to help automate manual processes. In our examples, we illustrate features like passing SAS language macro variables into a Python script for program generalization and task automation. We describe the bi-directional interchange of Python DataFrames and SAS datasets.
- We also illustrate the flexibility of using a SAS language program to execute a PySpark script to instantiate a Spark context, manipulate and download a Databricks table, and post-process the downloaded data with familiar SAS Data step statements and procedures.
Infrastructure
These examples were executed using SLC Version: 05.25.01 running on Windows 10. The Databricks cluster instance was deployed on Azure. It uses Databricks Runtime of 15.4 (Apache Spark 3.5.0, Scala 2.12) and Unity Catalog. And because this is a single-user test environment, it consists of a single 14GB, 4 Core driver node and two 28GB, 8 Core worker nodes.
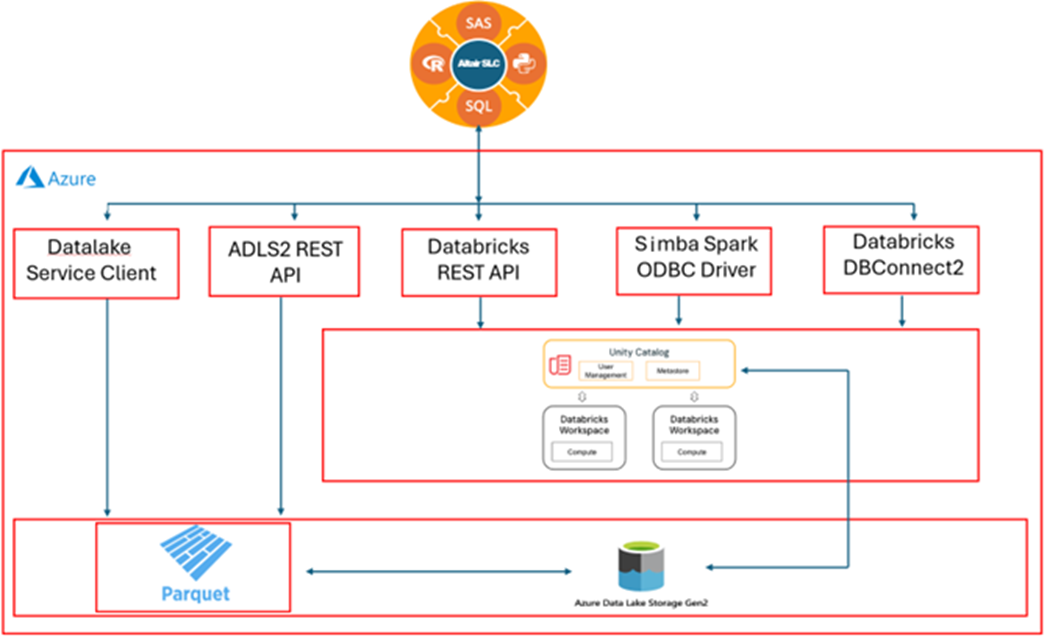
All the programs were executed locally using SLC on Windows desktop. The authentication mechanisms for Databricks used Personal Access Tokens read from a local environment variable. See Figure 1, Logical View of SLC and Databricks Integration on Azure.
These examples also illustrate read/write access to ADLS2 storage using blob storage for Parquet and Arrow files. The ADLS2 container was defined with a hierarchical name space enabled. This feature enables the ability to map the physical block storage format to a logical, hierarchical file system.
In some cases, authentication to ADLS2 was performed using a Signed Access String with an expiration length of 7 days. In other cases, authentication was performed using the ADLS2 account name and account authorization token. In both cases, these values were read from local environment variables.
Reading local environment variables for authentication tokens is not an acceptable practice in a production environment. Both Databricks and ADLS2 provide more robust authentication mechanisms. For example, see:
https://docs.databricks.com/aws/en/connect/storage/aad-storage-service-principal
These examples can also work with AWS, GCP, or other cloud-providers, given the ‘portability’ of the SAS language. In the case of the Python libraries, none of the Python program syntax is ‘portable’ since each cloud vendor will have their own libraries. To be clear, the PySpark syntax shown in the example Execute PySpark on a Databricks Cluster for Manipulation and Download Results as a SAS table, will work without modification since the instantiation of a Databricks cluster and the execution of PySpark is cloud independent.
Logical View of SLC and DataBricks Integration on azure
Figure 1: Logical View of SLC and Databricks Integration of Azure
MAP DATABRICKS DATA Using LIBREF VIA DATABRICKS LIBNAME ENGINE
The use of LIBNAME engines for database access is a common use case for users of the SAS language. In this case, the DATABRICK LIBNAME egine provides a relational data model on top of both input data such as Databricks data tables managed by Unity Catalog in a similar way to SAS datasets (.sas7bdat). In this example we assign the SAS libref DBCLUSTR to the Databricks dbcluster.slcdbs catalog.schema location. In the Databricks environment, dbcluster represents the catalog name and slcdbs represents the schema name.
As you can see from the PROC CONTENTS output, the dbcluster.slcdbs schema contains multiple data tables managed by Databricks. See Figure 2, PROC CONTENTS for Databricks for dbcluster.slcdbs schema.
%let databricks_host = %sysget(DATABRICKS_HOST_NOSCHEME);
%let databricks_token = %sysget(DATABRICKS_TOKEN);
%let databricks_http_path = %sysget(DATABRICKS_HTTP_PATH);
LIBNAME dbclustr DATABRICKSHOST="&databricks_host"
PORT="443"
DRIVER ="Simba Spark ODBC Driver"
HTTPPATH="&databricks_http_path"
AUTHMECH=11
AUTH_FLOW=0
SCHEMA=slcdbs
AUTH_ACCESSTOKEN="&databricks_token";
/* Test the connection */
proccontentsdata=dbclustr._all_;
run;
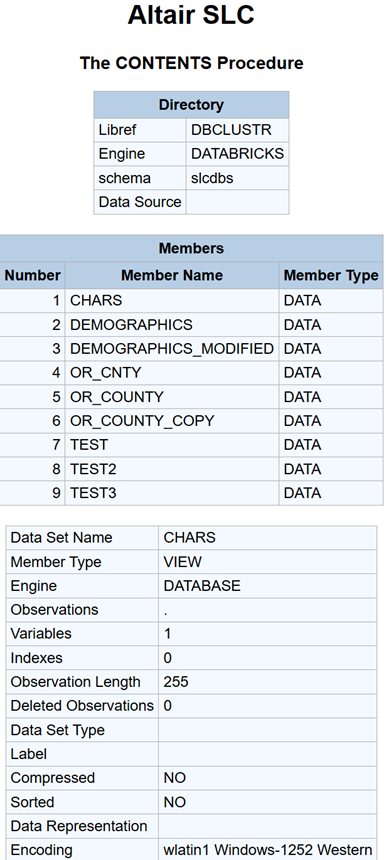
Figure 2: PROC CONTENTS for Databricks for dbclustr.slcdbs Schema
Bulk load SAS dataset to Databricks
A common use-case is bulk loading a SAS dataset to be managed as a Databricks SQL table. In this example the SAS dataset in_sas.policy_info is loaded as the Databricks table policy_info into the slcdbs Schema referenced above. We utilize the bulk load options as dataset options. The BDKEY=POLICY_INFO parameter sets this column as the primary key in the table.
The path to the bl_volume parameter writes to the Databricks DBFS file location. If you need to create this path before executing the bulk load you can use the Databricks UI or by executing the notebook command:
dbutils.fs.mkdirs("dbfs:/FileStore/tables/bulk_load")
libname in_sas sas7bdat"C:\SAS";
data dbclustr.policy_info(bulkload = yes
bl_volume = "dbfs:/FileStore/tables/bulk_load"
bl_delete_datafile = yes
dbkey=policy_info);
set in_sas.policy_info;
run;
procsql;
selectcount(*) into :db_rows
from dbclustr.policy_info;
quit;
%put ===> Row count for table dbclustr.policy_info: &db_rows;
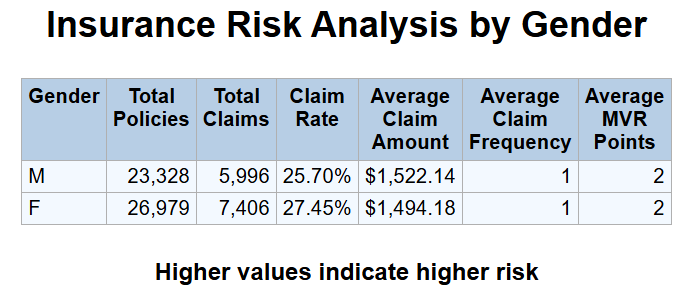
SLC Implict SQL Query to Databricks
PROCSQL;
CREATETABLE gender_risk AS
SELECT
d.GENDER LABEL="Gender"
, COUNT(p.policynum) AS total_policies FORMAT=comma10.
LABEL="Total*Policies"
, SUM(CASEWHEN p.CLM_FLAG = 'Yes'THEN1ELSE0END) AS total_claims FORMAT=comma10.
LABEL="Total*Claims"
, CALCULATED total_claims / CALCULATED total_policies AS claim_rate FORMAT=percent10.2
LABEL="Claim*Rate"
, AVG(p.CLM_AMT) AS avg_claim_amount FORMAT=dollar10.2
LABEL="Average*Claim*Amount"
, AVG(p.CLM_FREQ) AS avg_claim_frequency FORMAT=comma10.
LABEL="Average*Claim*Frequency"
, AVG(p.MVR_PTS) AS avg_motor_violation_points LABEL="Average*MVR*Points"
FROM dbclustr.Demographics d
, dbclustr.policy_info p
WHERE d.policynum = p.policynum
GROUP BY d.GENDER
ORDER BY avg_claim_frequency DESC, avg_claim_amount DESC;
QUIT;
PROCPRINTDATA=gender_risk
SPLIT="*"
LABEL
NOOBS;
TITLE"Insurance Risk Analysis by Gender";
FOOTNOTE"Higher values indicate higher risk";
run;
Resources
Altair SLC
https://altair.com/altair-slc
Databricks Access Connector Creation Video
Databricks SDK for Python
https://github.com/databricks/databricks-sdk-py?tab=readme-ov-file#databricks-native-authentication
Magnitude Simba Apache Spark ODBC Data Connector
https://docs.databricks.com/_extras/documents/Simba-Apache-Spark-ODBC-Connector-Install-and-Configuration-Guide.pdf
Introduction to Azure Data Lake Storage
https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
PySpark on Databricks
https://docs.databricks.com/aws/en/pyspark
Databricks SQL Language Reference
https://docs.databricks.com/aws/en/sql/language-manual
Databricks Execution Context API
https://docs.databricks.com/api/workspace/commandexecution/create
Databricks Run a Command API
https://docs.databricks.com/api/workspace/commandexecution/execute
Databricks Spark Session Get or Create
https://api-docs.databricks.com/python/pyspark/latest/pyspark.sql/api/pyspark.sql.SparkSession.builder.getOrCreate.html
Azure SDK for Python
https://learn.microsoft.com/en-us/azure/developer/python/sdk/azure-sdk-overview
DataLakeServicesClient Class
https://learn.microsoft.com/en-us/python/api/azure-storage-file-datalake/azure.storage.filedatalake.datalakeserviceclient?view=azure-python
Azure Data Lake Storage Gen2 REST APIs
https://learn.microsoft.com/en-us/rest/api/storageservices/data-lake-storage-gen2
Databricks Unity Catalog List Tables API
https://docs.databricks.com/api/azure/workspace/tables/list
