With a few changes to the template, this is my process.
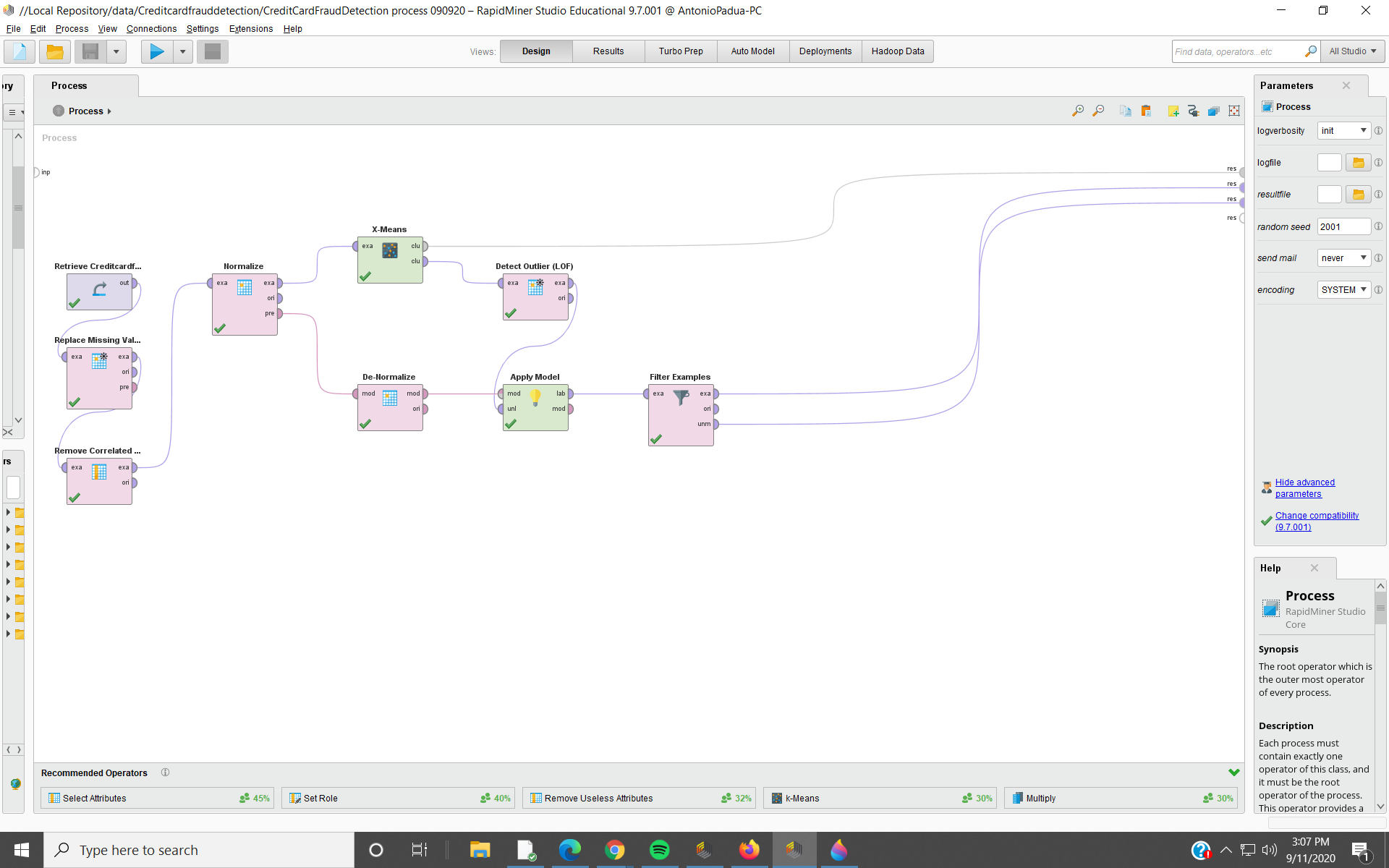
I used x-means and Detect Outlier (LOF) to detect possible fraud. The original data set contains over 284,000 rows. I selected out the first 3,000 rows for my first try.
These are the results, left half and right half. I see Outlier(s) from high to low.
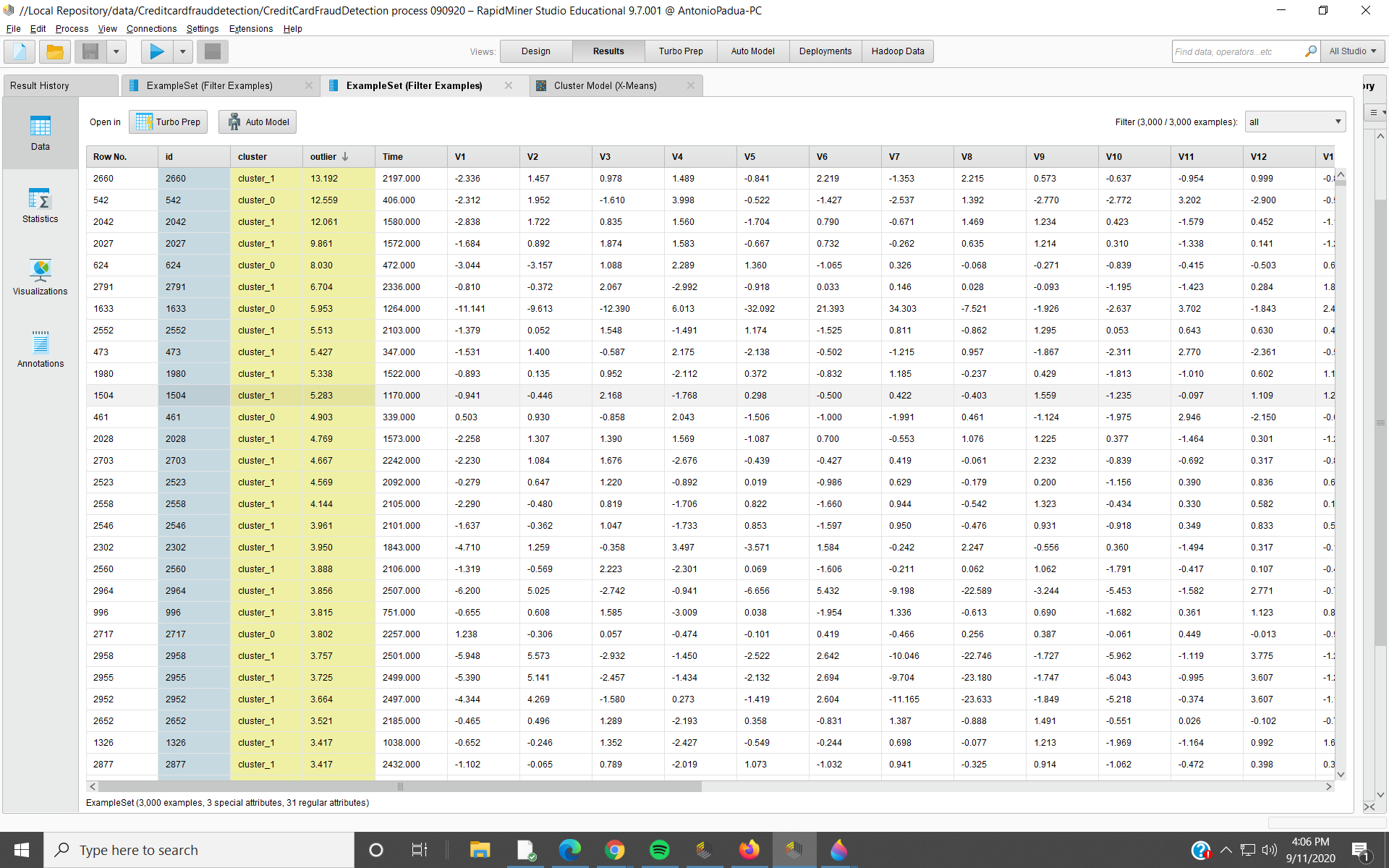
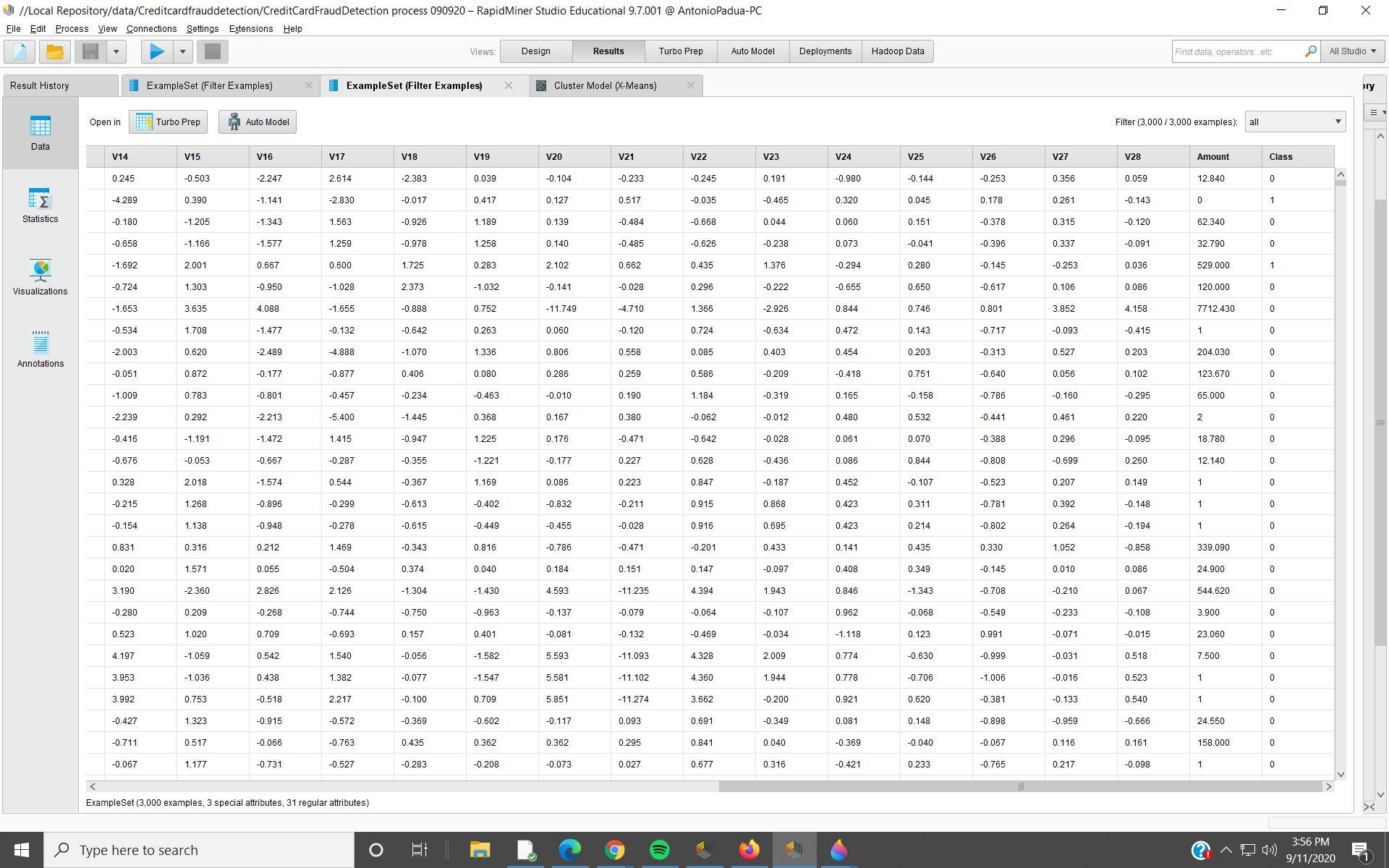
In the right half, I see Class = 1 only in rows 2 and 5. I would guess those are outliers.
Row 2 Outlier = 12.559. Row 5 Outlier = 8.030. There are higher value outliers nearby. Since both these have Class = 1, do I assume these are probably instances of fraud?
To compare, I selected out 5,000 rows for a bigger data set. Detect Outlier (LOF) took longer to run, but I got results. The process remained the same, the retrieve data set now has 5,000 rows.
This time Class = 1 happens twice, Outliers are 16.921 and 10.364, not high on the list of Outlier(s) from high to low.
Where Class = 1 (fraud?), should not Outlier scores be higher?
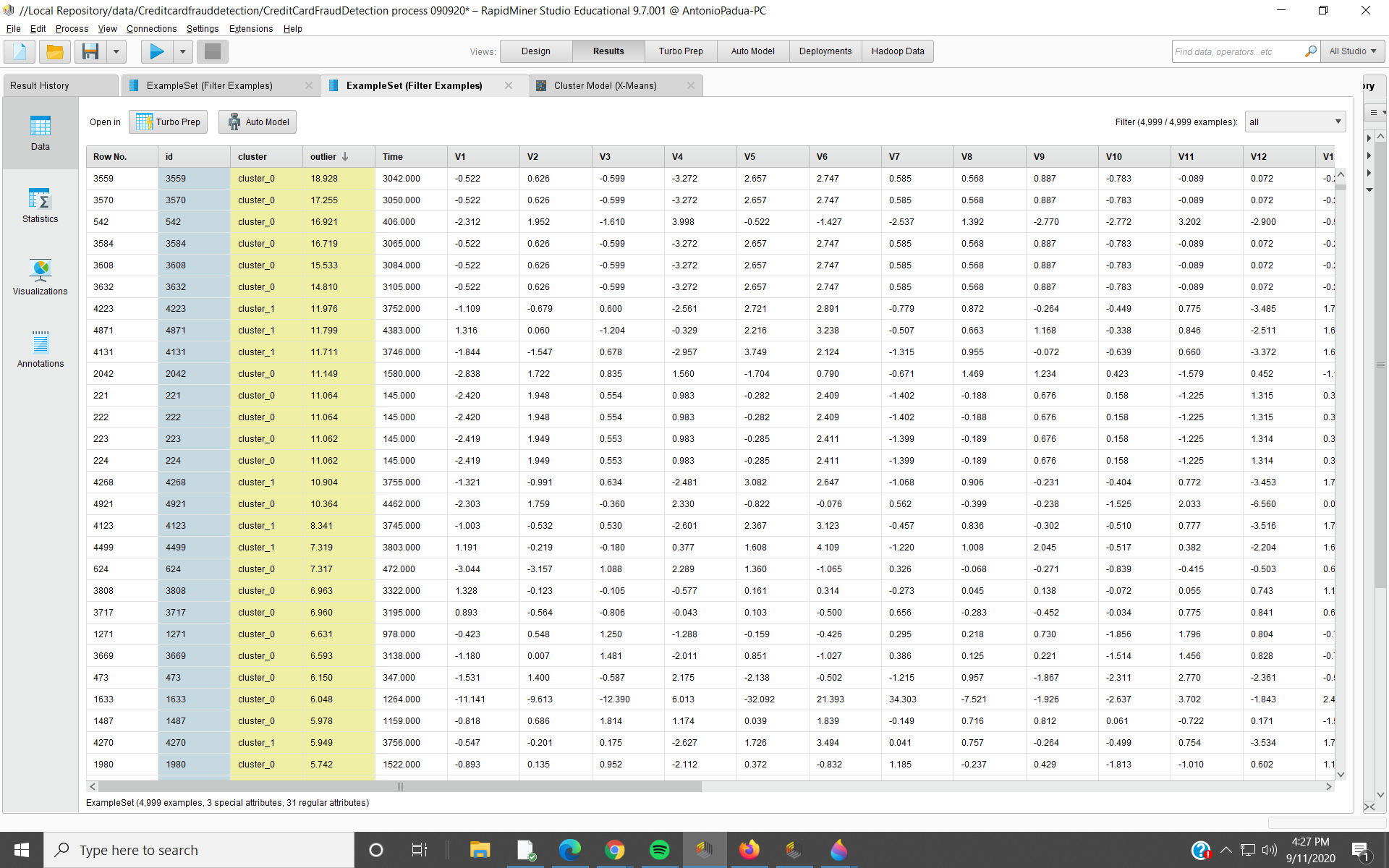

What am I possibly missing here?
Thanks for your time.
Tony


