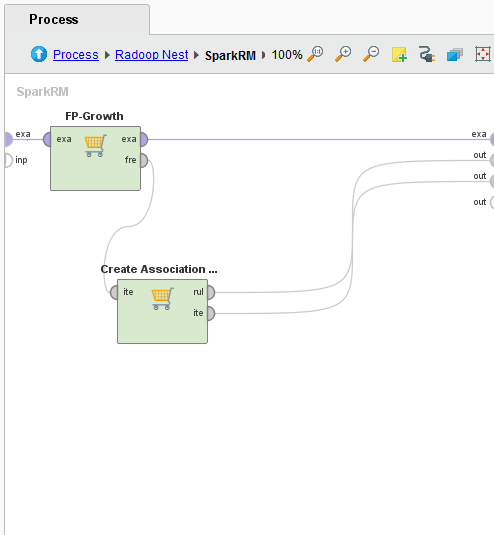
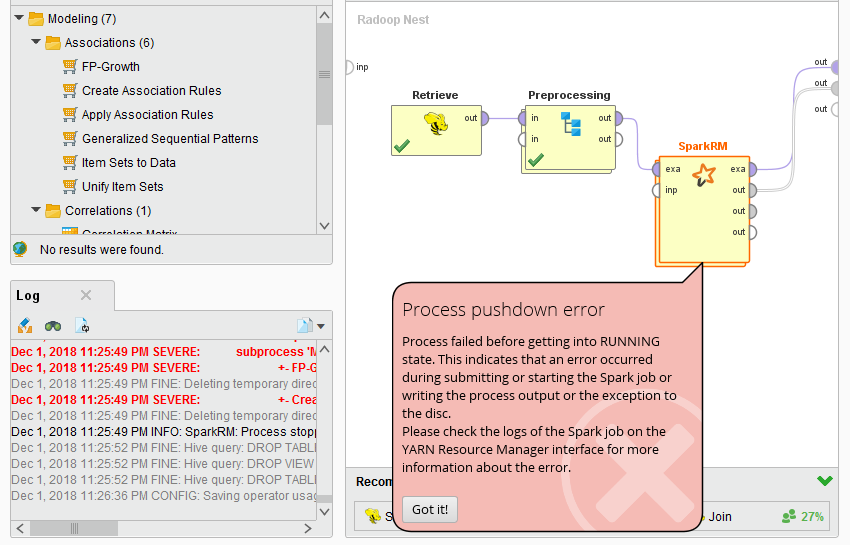
I'm working on radoop. I'm using the sparkRM to extract association rules. for that, I apply the fpgrowth in the sparkRM operator subprocess.
I have these error : SparkRM: The driver resource request has not yet been granted to the Spark job.
joined the process and the error.