シンプルなモデルを使用して、romAIの機能をチェックしていきます。第6回はデータの分割(Training Data/ Cross-Validation Data / TEST Data)について確認します。
データの分割について
第1回で軽く触れました内容を再掲します。
学習データはTESTデータとCross-Validationデータに分割されます。デフォルトでは、TESTデータが20%、Cross-Validationデータが25%となっています。したがって、残りの100%-20%-25%=55%のデータを用いて、パラメータの最適化が行われます。Cross-ValidationデータはEpoch毎にlossをチェックしますので、収束判定に利用できます。TESTデータはトレーニング完了後の答え合わせに使用されます。

データにノイズが多い場合は、55%のデータでパラメータの最適化を行い、25%のデータでCross-Validationを行いながら、過学習が起きないようパラメータを決めていくので良いと思いますが、綺麗なデータが準備できている場合は、55%のデータしかパラメータ最適化に使わないのはもったいない気がします。
また、準備した学習データが少ない場合も、さらにその55%しか使用しないのは不安が残ります。そこで、今回は、ほぼすべてのデータを学習データとして使うとどうなるかを見てみます。
問題設定
第4回と同様インパクト関数によるモデルです。データの分割比(Split Ratio)を変えて結果を比較してみます。

romAIの設定
romAIの設定を行います。
第1~5回と同様に、静的ROMとしてInputs、Outputsのみを指定します。

relu関数で[20,20]としました。

データ分割の設定
分割デフォルト
Testが20%、Cross-validationが25%で残りの55%がトレーニングに使用されます。
分割なしと条件を揃えるため、Early Stoppingは使用せず、Epochs = 100としました。

分割なし
TestとCross-validationにデータを割きたくない場合は、小さな数値(例えば1e-10)を入れてください。
最低1個ずつのデータがTestとCross-validation割り当てられ、全データ-2個のデータがトレーニングに使用されます。
Cross-validationは1データの値で行われるため、Cross-validationで求まるloss値は当てにならず、Early Stoppingは使用できません。Epochsで設定した回数のトレーニングを行い、計算終了となります。今回はEpochs = 100としました。

結果の比較
トレーニングのLossを比較すると、分割せずにほぼすべてのデータをトレーニングに使用したほうが、Lossが小さいことがわかります。

インパクト関数の波形と比較します。全体的には分割デフォルトでも分割なしでもインパクト関数を良く再現できています。

立ち上がり部分を拡大してみると、分割なしのほうが、インパクト関数に近いことがわかります。

まとめ
インパクト関数の再現を例に、データ分割の影響を確認しました。
今回は、学習データがノイズのない綺麗なデータであったため、TEST、Cross-validationのデータを減らし、ほぼすべてのデータをトレーニングに使用したほうが、Lossが小さく、インパクト関数の再現性も高いことを確認しました。
学習データの量や品質により調整してみてください。
補足1:
本ブログで使用したモデルとその解説動画は下記よりご利用いただけます。
パラメータを変えていろいろお試しください。
romAI検証(その6)学習データの分割 - Altair Community
補足2:
トレーニングデータの数が多すぎて、トレーニングに時間がかかりすぎる場合は、Test Split Ratioの値を大きくすることで、トレーニングデータを削減し、トレーニング時間を短縮できます。
たとえば、Test Split Ratio: 0.9 とすると、全データの90%をTestに使いますので、毎epochで使用するtraining と Cross-validationのデータは全データの10%となり、1epochあたりの計算時間が短くなります。
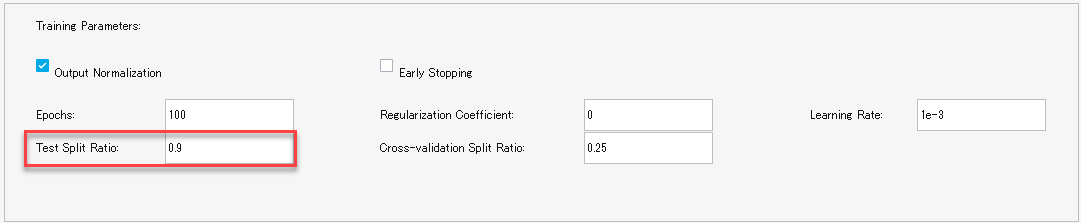
精度との兼ね合いになりますが、時間刻みが細かすぎてデータ量が多くなっている場合は有効かもしれません。
使用ソフト:
複合領域のモデルベース開発ソフトウェア | Altair Twin Activate

