Vehicle crash simulations are essential for automotive safety design, but they present a significant computational challenge. High-fidelity crash models can take hours or even days to complete a single simulation, making design exploration and optimization studies extremely time-consuming and costly. When engineers need to evaluate hundreds of design variations to optimize crash performance, traditional simulation approaches become impractical.
This computational bottleneck severely limits the ability to perform comprehensive design studies, sensitivity analyses, and real-time design decisions during the development process. Engineers are often forced to run limited numbers of simulations, potentially missing optimal design configurations.
Altair romAI addresses this challenge by creating neural network-based Reduced Order Models (ROMs) that capture the essential physics of crash simulations while running orders of magnitude faster than the original high-fidelity models. By training on existing simulation data, romAI can predict crash responses instantly, enabling extensive design exploration that would otherwise be computationally prohibitive.
This tutorial demonstrates the workflow using a front-end pole crash scenario at 8 km/h, where we want to understand how key structural parameters affect crash performance.
Context
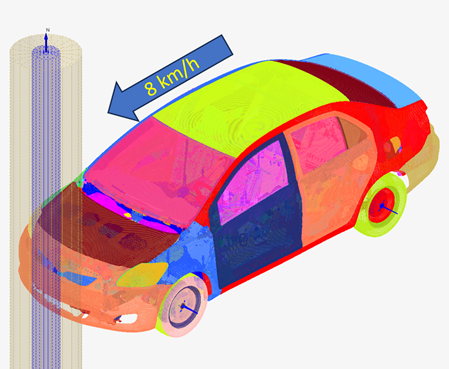
Figure 1. Simulation setup: Front-end pole car crash at 8 km/h.
The frontal crash simulation setup can be seen in figure 1. The first step involves identifying design parameters that significantly influence crash behavior. For this example, three critical structural parameters were selected (shown in figure 2):
- Crash-box thickness affects the energy absorption characteristics of the front structure.
- Cross-beam thickness influences the structural stiffness and load distribution during impact.
- Cross-beam material yield stress determines the deformation behavior and failure characteristics of this critical component.
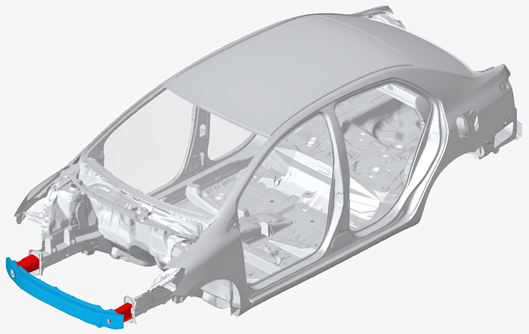
Figure 2. Car structural model. Crash-box highlighted in red and cross-beam highlighted in blue.
These parameters were chosen because they have substantial influence on the crash response and are commonly varied during automotive design optimization studies.
The crash performance metrics that the ROM will predict must also be defined. Four key outputs that capture different aspects of crash performance were selected:
- Head acceleration of the dummy represents occupant safety, as excessive head acceleration can cause serious injuries.
- Global intrusion into the car measures how much the crash structure deforms inward, affecting occupant space.
- Internal energy in the cross-beam quantifies the energy absorption capacity of this structural component.
- Force present in the pole indicates the peak forces transmitted during impact, which affects both structural integrity and occupant loads.
Having defined exploration space and performance metrics, a dataset must be created from several high-fidelity simulation results, and the ROM must be trained from it.
Dataset Generation
In this case, the dataset was created from 21 runs, exploring the design space of the parameters of interest, as seen in figure 3. Keep in mind that the size of a dataset is different for each use case, and yours might require more or less simulations.

Figure 3. Design exploration space. Each dot represents a simulation run with a specific crash-box thickness, cross-beam thickness, and cross-beam material yield stress.
It is good practice to also run some additional configurations within the design space and to separate them from the dataset that will be used for training. In that way, we can validate how the AI ROM responds to totally new scenarios. In this case, three additional scenarios (shown in green among the train/test scenarios) were run and kept in a separate validation dataset.
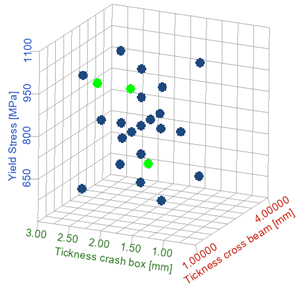
Figure 4. Design space of train/test (blue) and validation (green) runs.
Design parameters and key performance metrics for all runs are stored in two .csv datasets (train/test and validation), one run after the other, in this layout:
time | Cross-beam thickness | Crash-box thickness | Crash-box Yield | Head Acceleration | Global Intrusion | Internal Energy Cross-beam | Pole Force |
|---|
0 | 1.56 | 1.259 | 600 | -9.98E-05 | 0 | 0 | 0 |
1.001 | 1.56 | 1.259 | 600 | 0.000318 | 2.222 | 1.49E-08 | 0.04914 |
2.001 | 1.56 | 1.259 | 600 | 0.00012 | 4.458 | 2.61E-05 | 0.07347 |
3.001 | 1.56 | 1.259 | 600 | 0.0006 | 6.702 | 7.26E-05 | 0.06842 |
… | … | … | … | … | … | … | … |
You can find more information on how to easily create datasets for romAI here: Creating Datasets from Results Files for Altair romAI.
Training an AI Reduced Order Model
Once the data is ready, an AI surrogate model can be built very easily using romAI Director. The creation of a ROM should follow three steps:
- Pre-processing
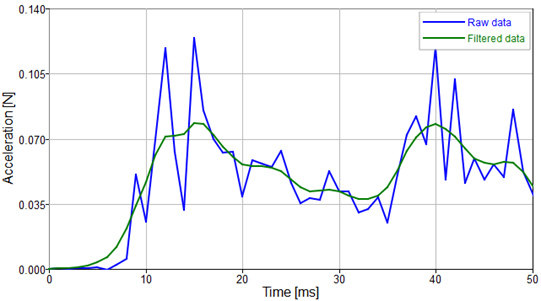
The dataset that will be used for training the ROM should be inspected in the pre-processor tab of romAI Director to check the quality of the signals. It may be possible some require filtering.
In this case, the only signal that requires filtering is the head acceleration (see figure 5). It can be very easily filtered to the desired frequency right here. I recommend exporting a new dataset with pre-processed signals into a new .csv file. Although signals can be exported directly into the next step of the process as well.
2. Training
Once the dataset has been pre-processed, the ROM can be defined and trained from the Builder tab. Users can define several parameters of the architecture and training process of the model. I recommend looking at this guide for good practices on setting these parameters: romAI - Tips & Tricks for Beginners. However, there are some additional recommendations for this kind of use case:
- For this application, the ROM needs to predict dynamic curves from static inputs (our design properties). For that reason, a nice little trick that has proven quite useful is to define time as an input and to define no states for the model:
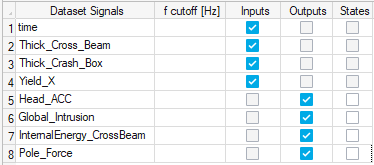
- Decoupled outputs: When defining several outputs from a single ROM, it’s a good idea to decouple the outputs to predict. In that way, a separate ROM is trained to predict each output, and all can be accessed within the same model. This often leads to improved performance. There is a “Decouple outputs” option in the Builder tab.
Note: The auto-exploration feature of romAI Director trains multiple ROMs over a set of architecture choices defined by the user. This can be quite useful when unsure about how many hidden layers, neurons, etc. to use.
3. Validating
Once the training is done. Metrics and performance of the ROM can be analyzed in the post-processor tab. The most important feature here is that we can test the model against runs from the training dataset as well as any other dataset (this is where the validation dataset is useful).
This model is quite accurate, look at how it predicts outputs from the validation dataset:
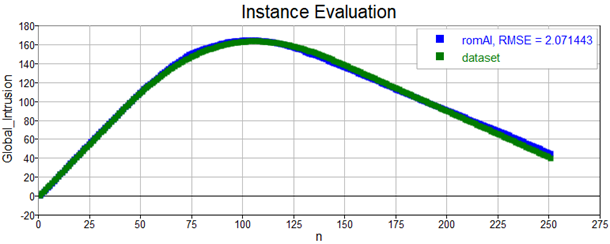
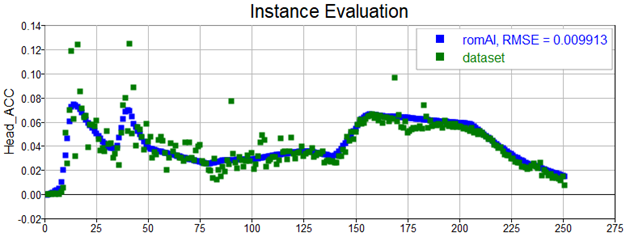
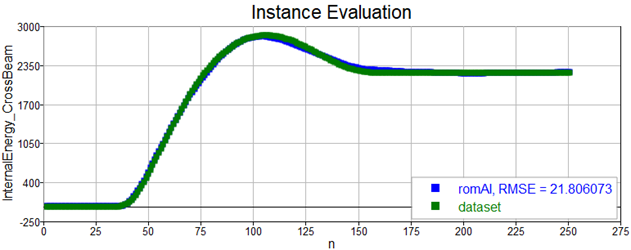
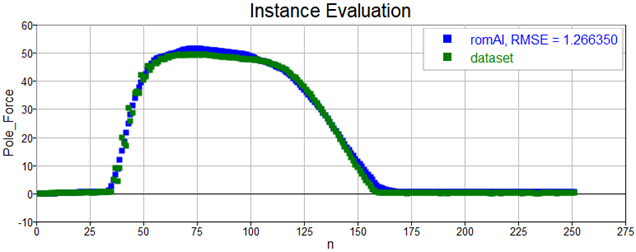
Once the surrogate model has been trained and its performance validated, we are ready to use it in our workflow, whether we want to test for specific scenario or use it in our optimizations instead of the high-fidelity model, using an AI ROM will accelerate simulation by several orders of magnitude!
You can have a deeper look at the files shown here:
