This document explains how to use the Graph Data Interface (GDI) to onboard relational data into Graph Studio.
It covers writing GDI queries, securing credentials, optimizing performance, and leveraging ontology-driven mappings to transform tabular data into a structured knowledge graph.
Contents
- Developer Checklist
- Understanding the Dataset
- GDI Query Structure
- Best Practices for Developers
- Troubleshooting Tips
- Leveraging the Ontology for Query Optimization
- Further Examples
_______________________________________________________________________________________
Developer Checklist
- Connect to the database: Use
s:DbSource, s:url, s:username, and s:password to define the connection. - Select data: Use
s:table for a full ingestion or s:query for a more targeted load. - Generate the graph: Ensure your query includes both
s:RdfGenerator and s:OntologyGenerator to create data triples and the model automatically. - Use partitioning: To optimize for large tables, use
s:partitionBy to enable parallel ingestion. - Secure credentials: Avoid hardcoding credentials. Use a secure Query Context to store and reference sensitive information.
_______________________________________________________________________________________
Understanding the Dataset
Suppose our database contains a table called public.Movies with fields such as: MovieID, Title, Year, Genre, Director & IMDBRating.
Our goal is to extract this data and transform it into RDF triples for use in our knowledge graph.
________________________________________________________________________________________
GDI Query Structure
1. Define the Data Source and Generator
GDI uses the s:DbSource class to define a relational database source.
The generator line (?generator a s:RdfGenerator, s:OntologyGenerator ; ...) is essential for invoking the RDF and Ontology Generators, which automate the mapping of tabular data to RDF triples.
The s:RdfGenerator and s:OntologyGenerator are key components of a GDI query:
s:RdfGenerator: This is responsible for the core task of converting our source data into RDF triples, which are the fundamental building blocks of a knowledge graph. It automatically transforms rows and columns from our relational database into a subject, predicate, and object structure. This is the "process of adding" data that we want to perform.s:OntologyGenerator: This is responsible for defining the semantic structure of our data. It automatically creates a data model (or ontology) that represents the schema of our source. This includes defining classes for our tables (e.g., a Movie class) and properties for our fields (e.g., title, year, rating). This is why the ontology generator is "essential" to the process.
2. Example GDI Transformation Query
Below is a sample GDI transformation query for onboarding data from a public.Movies table.
PREFIX public: <http://altair.com/DataSource/your-datasource-id/Top200Movies/public/>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
INSERT {
GRAPH ${targetGraph} {
?subject ?predicate ?object .
}
}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?generator a s:RdfGenerator, s:OntologyGenerator ;
s:as (?subject ?predicate ?object) ;
s:base ${targetGraph} .
public:Movies a s:DbSource ;
s:url "{{db.your-datasource-id.url}}" ;
s:username "{{db.your-datasource-id.user}}" ;
s:password "{{db.your-datasource-id.password}}" ;
s:database "{{db.your-datasource-id.database}}" ;
s:table "public.Movies" ;
s:model "Movies" ;
.
}
}
Key Elements
?generator a s:RdfGenerator, s:OntologyGenerator ; s:as (?subject ?predicate ?object) ; s:base ${targetGraph} .This line is required to invoke the GDI RDF and Ontology Generators, which automatically generate the graph and ontology for your data source.- s:DbSource:
Defines the database connection and extraction details, using context variables for sensitive information. - s:query:
Custom SQL query for data extraction.
________________________________________________________________________________________
Best Practices for Developers
a. Start Simple, Then Expand
Begin with a basic query to ensure connectivity and correct data extraction. For example, start by selecting just a few columns or limiting the number of rows.
b. Use Query Contexts
Never hardcode credentials. Always use context variables for URLs, usernames, and passwords for security and reusability.
c. Optimize for Performance
To effectively handle large-scale data ingestion, especially with tables that have millions of rows, we should optimize our queries to leverage GDI's parallel processing capabilities.
- Primary Optimization: Use
s:partitionBy: s:partitionBy is the most effective method for speeding up ingestion from large tables. - When we use this property, GDI automatically splits a single large query into multiple smaller queries ("buckets") based on a specified column (like a primary key).
- This prevents the source database from being overwhelmed and allows Graph Studio to process data in parallel, which is much more efficient.
- Secondary Tuning (
s:limit, s:offset): For development, testing, and pagination, we can still use s:limit to restrict the number of rows. Thes:offset property is used in combination with s:limit to page through results.
d. Advanced: Filtering and Aggregation
Suppose you want only movies with an IMDB rating above 8.0:
s:query '''
SELECT MovieID, Title, Year, Genre, Director, IMDB_Rating
FROM public.Movies
WHERE IMDB_Rating > 8.0
'''
________________________________________________________________________________________
Troubleshooting Tips
- Connection errors: Double-check your context variables and network access.
- Query errors: Validate your SQL directly in the database before using it in GDI.
- Performance issues: Use
partitionBy and limit clauses. - Mapping issues: Ensure your RDF mapping matches the column names and types.
________________________________________________________________________________________
Leveraging the Ontology for Query Optimization
Ontology awareness helps us leverage the GDI’s ability to push down filters to the source.
Here are the steps to explore the Ontology Structure .
- From the main menu, navigate to the Model section.
- In the Model section, click the filter icon.
- In the filter options, select the checkbox to show only system data.
- In the filtered list of ontologies, we will see the
Data Toolkit ontology. This is the ontology used by GDI.
- Click on the
DataToolkit ontology to inspect the classes, properties, and relationships that GDI has inferred.
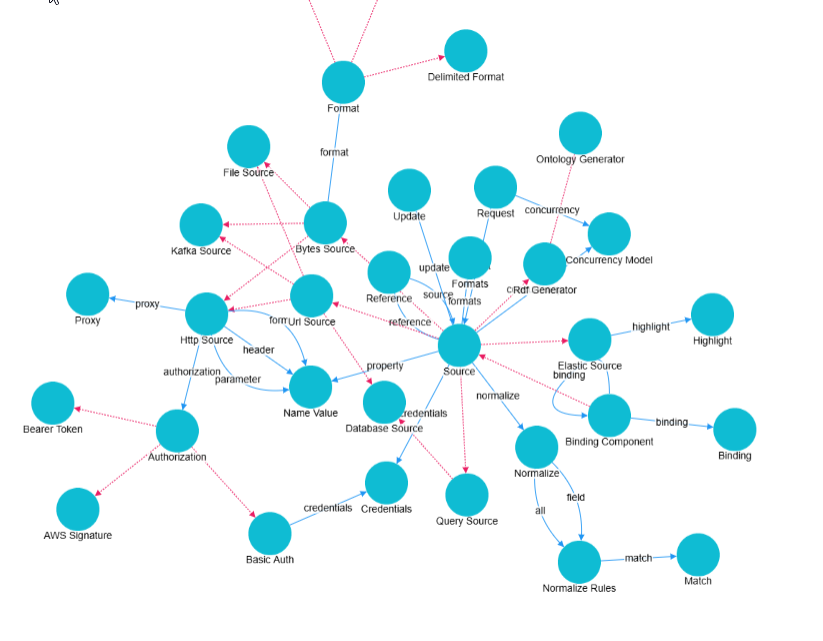
- Expand the relevant options on the left, helps us understand the structure and supported parameters in our ontology.
_____________________________________________________________________________________
Further Examples
1. Using s:partitionBy for Large Datasets
Suppose you want to extract the Top 200 Movies, but your table is very large and you want to avoid timeouts and memory issues.
PREFIX movies: <http://altair.com/DataSource/your-datasource-id/Top200Movies/public/>
PREFIX s: <http://cambridgesemantics.com/ontologies/DataToolkit#>
INSERT {
GRAPH ${targetGraph} {
?movie a movies:Movie ;
movies:title ?Title ;
movies:year ?Year .
}
}
WHERE {
SERVICE <http://cambridgesemantics.com/services/DataToolkit> {
?generator a s:RdfGenerator, s:OntologyGenerator ;
s:as (?subject ?predicate ?object) ;
s:base ${targetGraph} .
?movie a s:DbSource ;
s:url "{{db.movies.url}}" ;
s:username "{{db.movies.user}}" ;
s:password "{{db.movies.password}}" ;
s:database "{{db.movies.database}}" ;
s:table "public.Top200Movies" ;
s:model "Top200Movies" ;
s:partitionBy ("Year")) ; # Partition extraction by Year
s:limit 200 ;
s:query '''
SELECT MovieID, Title, Year
FROM public.Movies
ORDER BY IMDB_Rating DESC
LIMIT 200
''' .
}
}
Why use these?
s:partitionBy splits the extraction into separate partitions based on the values in the specified column (e.g., Year).
2. Using s:concurrency for Parallel Data Loads
To speed up ingestion by running multiple queries in parallel:
...
s:concurrency 4 ;
...
To speed up ingestion from very large tables, we can run multiple queries in parallel. This is especially useful when our database can handle multiple concurrent connections. For this to work effectively, we should always pair s:concurrency with s:partitionBy.
s:concurrency: This property sets the maximum number of parallel cores (also referred to as slices in the documentation) that GDI can use to execute our query.
3. Locale-Specific Parsing with s:locale
If your data contains locale-specific formats (e.g., dates, numbers):
...
s:locale "en_US" ; # Use US English locale for parsing
...
This ensures that numbers and dates are interpreted correctly.
4. Model and Key for Entity Mapping
If you want to specify a model and a unique key for entity resolution:
...
s:model "Movies" ;
s:key ("MovieID") ;
...
The s:model Property: Defining Classes
s:model maps a table or query to an RDF class in the ontology (e.g., s:model "Movie" creates a Movie class). This adds semantic structure so the data isn’t just triples but a queryable schema.
The s:key Property: Unique Identities
s:key defines the primary key column to generate unique URIs (e.g., s:key ("MovieID")). This guarantees each row is a distinct entity and can be linked across sources.
5. Example: Data Normalization with s:normalize
This lets us control how names (labels and URIs) are created for classes and properties when we bring data into Graph Studio from different sources.
This means we can set rules to make sure the names in our data model are consistent, clean, and follow preferred style or standards
...
s:normalize true ;
...
Or specify rules:
...
s:normalize [ s:trim true ; s:lowercase true ] ;
...
6. Using s:formats for Data Type Formatting
If you want to control how certain datatypes are formatted:
...
s:formats [
s:dateFormat "yyyy-MM-dd" ;
s:numberFormat "#,##0.##" ;
s:delimiter "," ;
s:headerRow true
] ;
...
s:formats block is especially important when your data uses non-default formats or when you want to avoid parsing errors during integration
7. Reference and Foreign Key Joins
Suppose you want to join with a related table (e.g., Directors):
...
s:reference [
s:model "Directors" ;
s:using ("DirectorID")
] ;
...
This tells GDI how to resolve relationships between tables.
_______________________________________________________________________________________
Further Reading:
____________________________________________________________________________________
Related Discussions
Pre-Requisites for Database Connectivity
Connecting Graph Studio to External Databases
