Hello RM forum,
I'd like to extract
all matches from an example set to a new attribute or even to multiple new attributes.
Example text:We love DOGS. But CATS are cooler than BROWN FOXES.
This is my RegEx which finds all occurences (operator "generate extract":
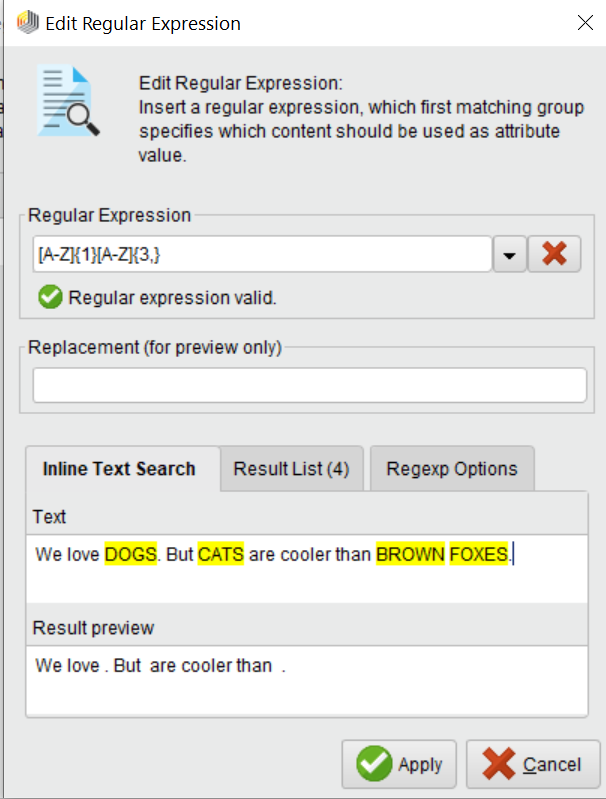
The Problem is, that it will only generate the first match as a new attribute:
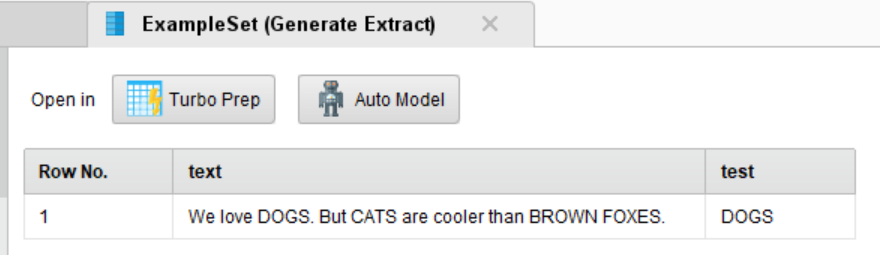
I want to get a new attribute containing all matches like:
test
DOGS;CATS;BROWN;FOXES
<?xml version="1.0" encoding="UTF-8"?><process version="9.7.002">
<context>
<input/>
<output/>
<macros/>
</context>
<operator activated="true" class="process" compatibility="9.7.002" expanded="true" name="Process">
<parameter key="logverbosity" value="init"/>
<parameter key="random_seed" value="2001"/>
<parameter key="send_mail" value="never"/>
<parameter key="notification_email" value=""/>
<parameter key="process_duration_for_mail" value="30"/>
<parameter key="encoding" value="SYSTEM"/>
<process expanded="true">
<operator activated="true" class="utility:create_exampleset" compatibility="9.7.002" expanded="true" height="68" name="Create ExampleSet" width="90" x="246" y="238">
<parameter key="generator_type" value="comma separated text"/>
<parameter key="number_of_examples" value="100"/>
<parameter key="use_stepsize" value="false"/>
<list key="function_descriptions"/>
<parameter key="add_id_attribute" value="false"/>
<list key="numeric_series_configuration"/>
<list key="date_series_configuration"/>
<list key="date_series_configuration (interval)"/>
<parameter key="date_format" value="yyyy-MM-dd HH:mm:ss"/>
<parameter key="time_zone" value="SYSTEM"/>
<parameter key="input_csv_text" value="text We love DOGS. But CATS are cooler than BROWN FOXES."/>
<parameter key="column_separator" value=","/>
<parameter key="parse_all_as_nominal" value="false"/>
<parameter key="decimal_point_character" value="."/>
<parameter key="trim_attribute_names" value="true"/>
</operator>
<operator activated="true" class="text:generate_extract" compatibility="9.3.001" expanded="true" height="68" name="Generate Extract" width="90" x="447" y="238">
<parameter key="source_attribute" value="text"/>
<parameter key="query_type" value="Regular Expression"/>
<list key="string_machting_queries"/>
<parameter key="attribute_type" value="Nominal"/>
<list key="regular_expression_queries">
<parameter key="test" value="[A-Z]{1}[A-Z]{3,}"/>
</list>
<list key="regular_region_queries"/>
<list key="xpath_queries"/>
<list key="namespaces"/>
<parameter key="ignore_CDATA" value="true"/>
<parameter key="assume_html" value="true"/>
<list key="index_queries"/>
<list key="jsonpath_queries"/>
</operator>
<connect from_op="Create ExampleSet" from_port="output" to_op="Generate Extract" to_port="Example Set"/>
<connect from_op="Generate Extract" from_port="Example Set" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
</process>
</operator>
</process>
Is there a way to do this in Rapidminer?
Kind regards,
Patrick


