Apologies for cc’ing everyone, but I really need some help!
I have a data set which started with 15 attributes and the two calculations which were needed to create the labels in excel (the label has three distinct values, but for my purposes, I’m only interested in two of them). The data is a time series with about 1300 periods/5+ years for training and 250 periods/1 year for testing. In RapidMiner, I calculate 20 period aggregations and create windows of 10 periods.
Using the full feature set, I trained a GBT that is about 65% accurate in training:
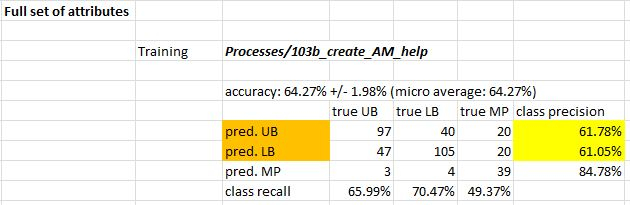
The testing performance is “really bad”, however, less than 50% accuracy:
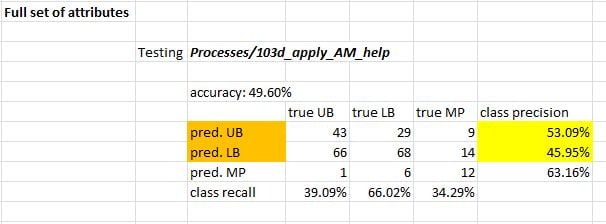
Note: I think I’ve attached all the relevant files: Data_Labeler_v16_help.xlsm (the labeler), help.xlsx (the data), 103b_create_AM_help.rmp (training process), and 103d_apply_AM_help.rmp (testing process).
I’ve been most focused on improving the testing accuracy and with Ingo’s “Multi-Objective Feature Selection” series, have been working with the Optimize Selection (Evolutionary) and Automatic Feature Engineering operators. AFE has worked “best” so far.
Training the GBT using the AFE feature set achieves just over 65% accuracy:
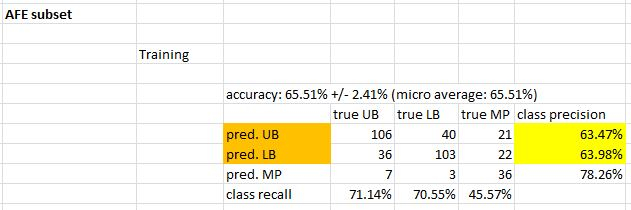
and ~55% in testing...
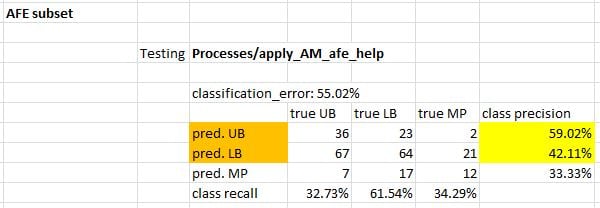
Headed in the right direction, but still a ways to go.
I’ve also included the AFE training process, AM_afe_help.rmp, and apply_AM_afe_help.rmp (for testing). The AFE ran for a while so I also included the feature set “features_AM_afe_help” and model “model_AM_process_afe_help”.
My question is this: how can I squeeze some more accuracy from this data (especially testing/out of sample accuracy)? Any suggestions are much appreciated… I’m trying to demonstrate a win for machine learning in my firm’s area of interest, but I only have another week to do it in.
Many thanks,
Noel












