The Siemens Community Catalyst program was co-created with our community to acknowledge technology leaders who consistently contribute to the Siemens Community. Nominations are accepted on a rolling basis.
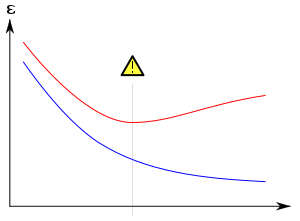
As the numb er of nodes in the decision tree increases, the tree will have fewer tralnmg and test errors. However, once the tree becomes too large, its test error begins to increase even though its training error rate continues to decrease. This phenomenon is known as model overfitting.
Can RM generate such a graph?
tek wrote:Is it save to say that in this example after the 17th iteration the overfitting begins to show effect?
wessel wrote:Do you have lots of input variables?
Maybe you have too many noisy inputs.
<?xml version="1.0" encoding="UTF-8" standalone="no"?><process version="5.1.006"> <context> <input/> <output/> <macros/> </context> <operator activated="true" class="process" compatibility="5.1.006" expanded="true" name="Process"> <process expanded="true" height="365" width="750"> <operator activated="true" class="retrieve" compatibility="5.1.006" expanded="true" height="60" name="Retrieve" width="90" x="112" y="30"> <parameter key="repository_entry" value="//Samples/data/Polynomial"/> </operator> <operator activated="true" class="loop_parameters" compatibility="5.1.006" expanded="true" height="94" name="Loop Parameters" width="90" x="313" y="30"> <list key="parameters"> <parameter key="Neural Net.training_cycles" value="[1;1000000;100;logarithmic]"/> </list> <process expanded="true" height="365" width="882"> <operator activated="true" class="split_data" compatibility="5.1.006" expanded="true" height="94" name="Split Data" width="90" x="45" y="120"> <enumeration key="partitions"> <parameter key="ratio" value="0.3"/> <parameter key="ratio" value="0.7"/> </enumeration> </operator> <operator activated="true" class="neural_net" compatibility="5.1.006" expanded="true" height="76" name="Neural Net" width="90" x="179" y="30"> <list key="hidden_layers"/> <parameter key="training_cycles" value="1000000"/> <parameter key="decay" value="true"/> <parameter key="shuffle" value="false"/> <parameter key="error_epsilon" value="0.0"/> </operator> <operator activated="true" class="multiply" compatibility="5.1.006" expanded="true" height="94" name="Multiply" width="90" x="313" y="120"/> <operator activated="true" class="apply_model" compatibility="5.1.006" expanded="true" height="76" name="Apply Model (2)" width="90" x="447" y="255"> <list key="application_parameters"/> </operator> <operator activated="true" class="performance_regression" compatibility="5.1.006" expanded="true" height="76" name="Performance (2)" width="90" x="581" y="255"/> <operator activated="true" class="apply_model" compatibility="5.1.006" expanded="true" height="76" name="Apply Model" width="90" x="447" y="30"> <list key="application_parameters"/> </operator> <operator activated="true" class="performance_regression" compatibility="5.1.006" expanded="true" height="76" name="Performance" width="90" x="581" y="30"/> <operator activated="true" class="log" compatibility="5.1.006" expanded="true" height="94" name="Log" width="90" x="715" y="120"> <list key="log"> <parameter key="Count" value="operator.Neural Net.parameter.training_cycles"/> <parameter key="TrainingError" value="operator.Performance.value.root_mean_squared_error"/> <parameter key="TestError" value="operator.Performance (2).value.root_mean_squared_error"/> </list> </operator> <connect from_port="input 1" to_op="Split Data" to_port="example set"/> <connect from_op="Split Data" from_port="partition 1" to_op="Neural Net" to_port="training set"/> <connect from_op="Split Data" from_port="partition 2" to_op="Apply Model (2)" to_port="unlabelled data"/> <connect from_op="Neural Net" from_port="model" to_op="Multiply" to_port="input"/> <connect from_op="Neural Net" from_port="exampleSet" to_op="Apply Model" to_port="unlabelled data"/> <connect from_op="Multiply" from_port="output 1" to_op="Apply Model" to_port="model"/> <connect from_op="Multiply" from_port="output 2" to_op="Apply Model (2)" to_port="model"/> <connect from_op="Apply Model (2)" from_port="labelled data" to_op="Performance (2)" to_port="labelled data"/> <connect from_op="Performance (2)" from_port="performance" to_op="Log" to_port="through 2"/> <connect from_op="Apply Model" from_port="labelled data" to_op="Performance" to_port="labelled data"/> <connect from_op="Performance" from_port="performance" to_op="Log" to_port="through 1"/> <portSpacing port="source_input 1" spacing="0"/> <portSpacing port="source_input 2" spacing="0"/> <portSpacing port="sink_performance" spacing="0"/> <portSpacing port="sink_result 1" spacing="0"/> <portSpacing port="sink_result 2" spacing="0"/> <portSpacing port="sink_result 3" spacing="0"/> </process> </operator> <connect from_op="Retrieve" from_port="output" to_op="Loop Parameters" to_port="input 1"/> <connect from_op="Loop Parameters" from_port="result 1" to_port="result 1"/> <connect from_op="Loop Parameters" from_port="result 2" to_port="result 2"/> <portSpacing port="source_input 1" spacing="0"/> <portSpacing port="sink_result 1" spacing="0"/> <portSpacing port="sink_result 2" spacing="0"/> <portSpacing port="sink_result 3" spacing="0"/> </process> </operator></process>
wessel wrote:Also you should add another loop around the "Loop Parameters" operator.And then change your "Log" operator to log the "Loop"-iteration.