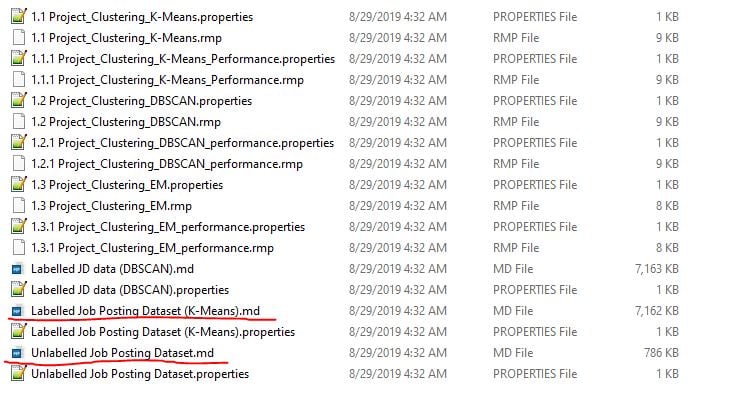
Hello,
I am of course a newbie, and I am trying to open an existing project which is the following:
the project has a lot of resources, and I am unable to open them (you can see that in the picture)
The second problem is I can't open the
.md files which contain the data for the project.
And for the file with the extension
.properties i don't know how and where to use them,
for example the clustering. properties contains the following scrip
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "">
<properties>
<comment>Properties of repository entry Clustering</comment>
<entry key="owner">zhaohengrui</entry>
</properties>I search a lot for a similar thing, but I didn't find, Apologies if this is has been asked before and I didn't see it.
Thank you