The post can be seen here:
https://community.rapidminer.com/discussion/58722/is-automodel-on-break-or-is-it-just-me#latestI tried the same "churn" problem dataset, this time using RapidMiner Go, which will cost you $10 per month.
Of the original dataset I used .7 to train, .3 to test.
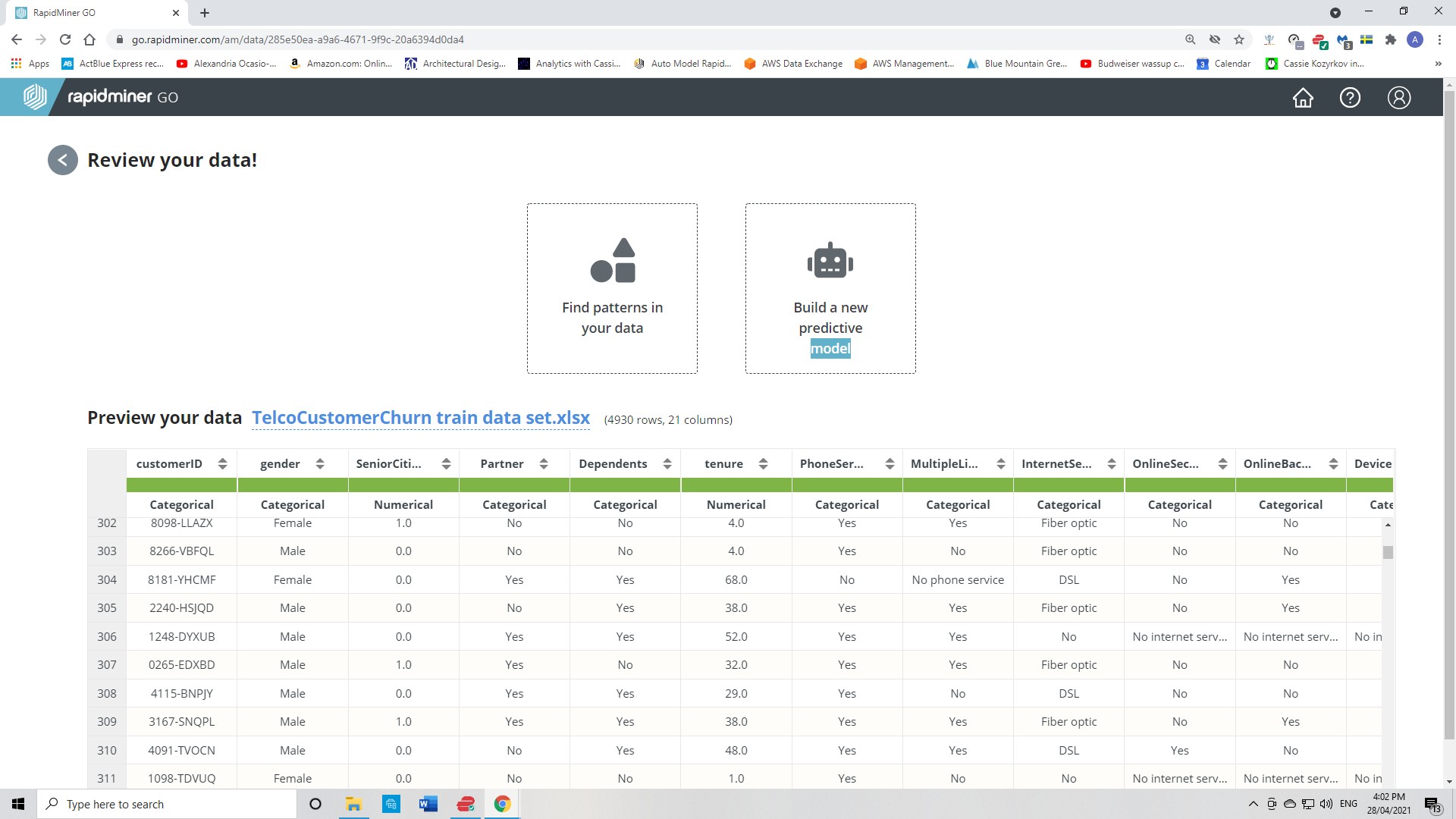
This is the preview of the train dataset.
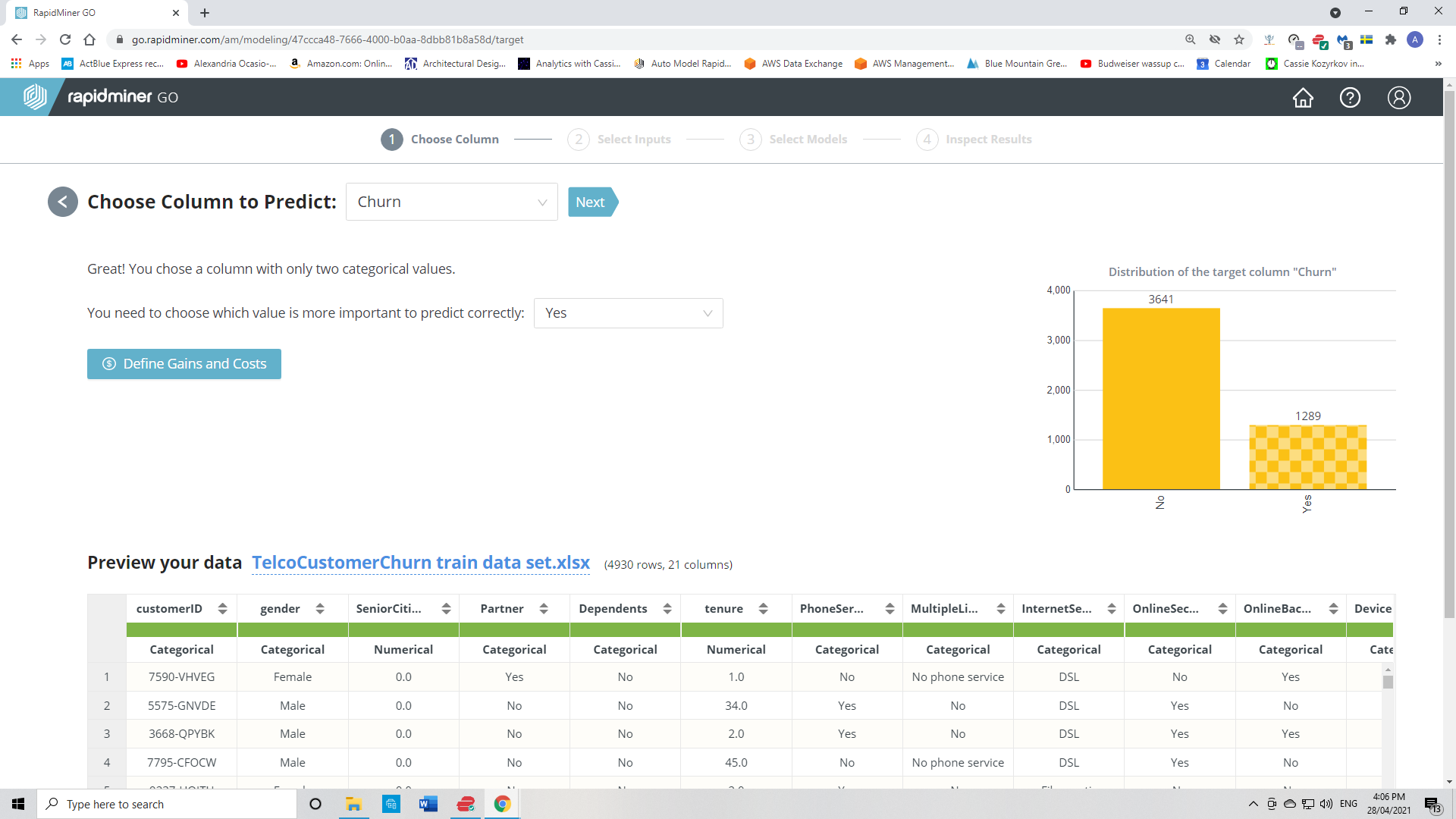
I build a new predictive model. I choose the column to predict: Churn.
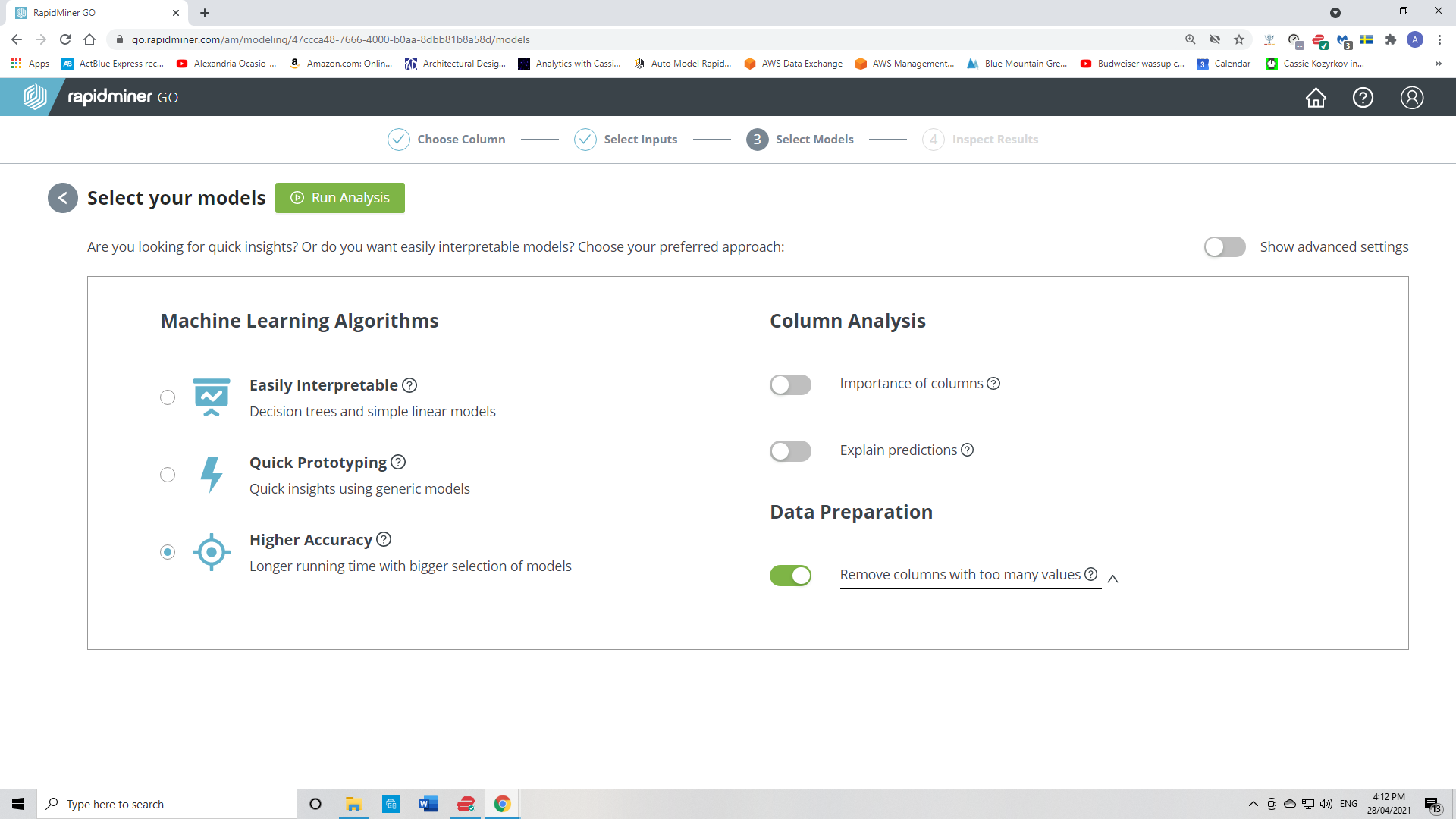
Go
removes the columns that have quality issues from my data. Next. I select my models, run analysis, choose higher accuracy.
I run the analysis. Go produces a Comparison table with Accuracy rates across nine separate algorithms.

I click on Generalized Linear Model with both highest precision and highest AUC. I get results for predicting churn on the train dataset.

I click to Apply Model to the test dataset. I get Check (test) dataset. The model ignores the target attribute Churn when generating predictions.

I calculate predictions, inspect predictions.

This problem was written about here:
https://medium.com/@ODSC/data-driven-artificial-intelligence-ai-for-churn-reduction-90232c1a0c4The author chose the logistic regression algorithm, shown as slightly less accurate by RM Go.
Her AUC is slightly smaller, maybe because she started with the less accurate algorithm.
She came to the same predictions as I did with RM Go: telco customers will be churning mainly because of problems with Fiber optic and DSL services.
She probably used up hours of resource time writing then debugging Python.
I am not being smug here, but if RapidMiner Go can work with my datasets no problem, can you agree RapidMiner Auto Model needs more work?
Any helpful suggestions are appreciated. If I'm to use RapidMiner Studio on the job, I need to know beforehand when I'm going wrong.
Thank you for plodding your way through this whole thing.
Tony

