Dear RapiderMiner Community,
I have the
following problem and hope you can help me with it: I have a sample
of different texts with IDs (data imported form Excel) and a list of word
sequences containing four words each (4-grams, also imported from Excel). I
would like to have a matrix which shows me how often each of the 4-grams of the
list appears in each of the texts.
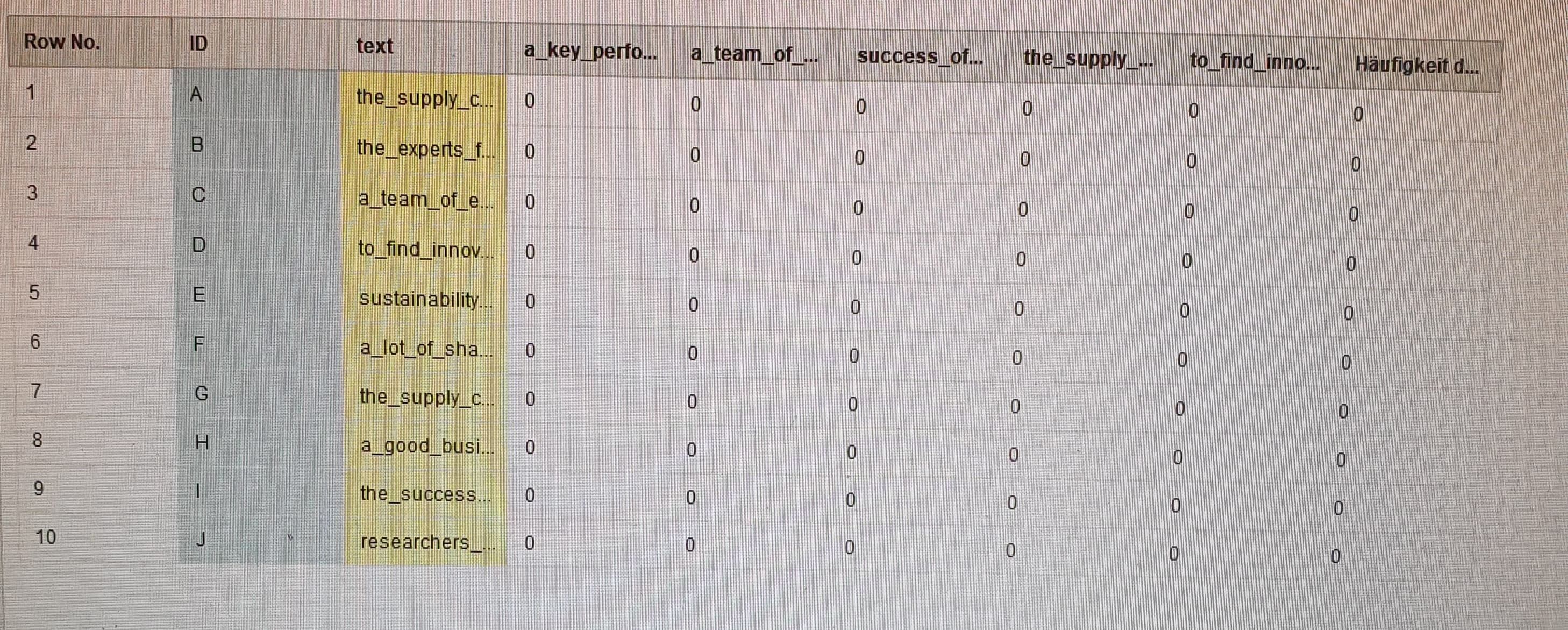
In my current
process I get a matrix which looks like the one I would like to have (picture
in the attachment), but „0“ is the only number displayed in the columns. In
other words, RapidMiner does not find the 4-grams in the texts, although I know
they occur in them. To help you
imagining what I mean I created and attached an example set of texts and
4-grams to this post (already as RapidMiner sample sets and as an Excel with two tabs). Each of the 4-grams should be in some of the texts. At the end of this text box
you can find my current process.
The real data set and 4-gram list are much bigger, so just creating n-grams with "Process Documents from Data" and picking the ones I need will not work unfortunately.
Thank you
very much in advance for your support.
Sincerely
<?xml version="1.0" encoding="UTF-8"?><process version="9.5.001">
<context>
<input/>
<output/>
<macros/>
</context>
<operator activated="true" class="process" compatibility="9.4.000" expanded="true" name="Process">
<parameter key="logverbosity" value="init"/>
<parameter key="random_seed" value="2001"/>
<parameter key="send_mail" value="never"/>
<parameter key="notification_email" value=""/>
<parameter key="process_duration_for_mail" value="30"/>
<parameter key="encoding" value="SYSTEM"/>
<process expanded="true">
<operator activated="true" class="retrieve" compatibility="9.5.001" expanded="true" height="68" name="Retrieve" width="90" x="45" y="238">
<parameter key="repository_entry" value="../data/Boilerplates/Community_example_4-Gram_list"/>
</operator>
<operator activated="true" class="text:process_document_from_data" compatibility="8.2.000" expanded="true" height="82" name="Process Documents from Data (3)" width="90" x="179" y="238">
<parameter key="create_word_vector" value="true"/>
<parameter key="vector_creation" value="Binary Term Occurrences"/>
<parameter key="add_meta_information" value="true"/>
<parameter key="keep_text" value="false"/>
<parameter key="prune_method" value="none"/>
<parameter key="prune_below_percent" value="3.0"/>
<parameter key="prune_above_percent" value="30.0"/>
<parameter key="prune_below_rank" value="0.05"/>
<parameter key="prune_above_rank" value="0.95"/>
<parameter key="datamanagement" value="double_sparse_array"/>
<parameter key="data_management" value="auto"/>
<parameter key="select_attributes_and_weights" value="false"/>
<list key="specify_weights"/>
<process expanded="true">
<operator activated="true" class="text:transform_cases" compatibility="8.2.000" expanded="true" height="68" name="Transform Cases (5)" width="90" x="514" y="34">
<parameter key="transform_to" value="lower case"/>
</operator>
<connect from_port="document" to_op="Transform Cases (5)" to_port="document"/>
<connect from_op="Transform Cases (5)" from_port="document" to_port="document 1"/>
<portSpacing port="source_document" spacing="0"/>
<portSpacing port="sink_document 1" spacing="0"/>
<portSpacing port="sink_document 2" spacing="0"/>
</process>
</operator>
<operator activated="true" class="multiply" compatibility="9.5.001" expanded="true" height="82" name="Multiply (2)" width="90" x="313" y="238"/>
<operator activated="true" class="retrieve" compatibility="9.5.001" expanded="true" height="68" name="Retrieve (2)" width="90" x="45" y="34">
<parameter key="repository_entry" value="../data/Boilerplates/Community_example_texts"/>
</operator>
<operator activated="true" class="text:process_document_from_data" compatibility="8.2.000" expanded="true" height="82" name="Process Documents from Data (2)" width="90" x="179" y="34">
<parameter key="create_word_vector" value="false"/>
<parameter key="vector_creation" value="TF-IDF"/>
<parameter key="add_meta_information" value="true"/>
<parameter key="keep_text" value="true"/>
<parameter key="prune_method" value="none"/>
<parameter key="prune_below_percent" value="3.0"/>
<parameter key="prune_above_percent" value="30.0"/>
<parameter key="prune_below_rank" value="0.05"/>
<parameter key="prune_above_rank" value="0.95"/>
<parameter key="datamanagement" value="double_sparse_array"/>
<parameter key="data_management" value="auto"/>
<parameter key="select_attributes_and_weights" value="false"/>
<list key="specify_weights"/>
<process expanded="true">
<operator activated="true" class="text:tokenize" compatibility="8.2.000" expanded="true" height="68" name="Tokenize" width="90" x="112" y="34">
<parameter key="mode" value="non letters"/>
<parameter key="characters" value=".:"/>
<parameter key="language" value="English"/>
<parameter key="max_token_length" value="3"/>
</operator>
<operator activated="true" class="text:transform_cases" compatibility="8.2.000" expanded="true" height="68" name="Transform Cases (3)" width="90" x="313" y="34">
<parameter key="transform_to" value="lower case"/>
</operator>
<operator activated="true" class="text:generate_n_grams_terms" compatibility="8.2.000" expanded="true" height="68" name="Generate n-Grams (Terms)" width="90" x="514" y="34">
<parameter key="max_length" value="4"/>
</operator>
<operator activated="true" class="text:filter_tokens_by_content" compatibility="8.2.000" expanded="true" height="68" name="Filter Tokens (by Content)" width="90" x="648" y="34">
<parameter key="condition" value="matches"/>
<parameter key="regular_expression" value="^\w+_\w+_\w+_\w+"/>
<parameter key="case_sensitive" value="false"/>
<parameter key="invert condition" value="false"/>
</operator>
<connect from_port="document" to_op="Tokenize" to_port="document"/>
<connect from_op="Tokenize" from_port="document" to_op="Transform Cases (3)" to_port="document"/>
<connect from_op="Transform Cases (3)" from_port="document" to_op="Generate n-Grams (Terms)" to_port="document"/>
<connect from_op="Generate n-Grams (Terms)" from_port="document" to_op="Filter Tokens (by Content)" to_port="document"/>
<connect from_op="Filter Tokens (by Content)" from_port="document" to_port="document 1"/>
<portSpacing port="source_document" spacing="0"/>
<portSpacing port="sink_document 1" spacing="0"/>
<portSpacing port="sink_document 2" spacing="0"/>
</process>
</operator>
<operator activated="true" class="set_role" compatibility="9.5.001" expanded="true" height="82" name="Set Role" width="90" x="313" y="34">
<parameter key="attribute_name" value="text"/>
<parameter key="target_role" value="regular"/>
<list key="set_additional_roles">
<parameter key="text" value="regular"/>
</list>
</operator>
<operator activated="true" class="multiply" compatibility="9.5.001" expanded="true" height="82" name="Multiply" width="90" x="313" y="136"/>
<operator activated="true" class="text:process_document_from_data" compatibility="8.1.000" expanded="true" height="82" name="Process Documents from Data" width="90" x="514" y="289">
<parameter key="create_word_vector" value="true"/>
<parameter key="vector_creation" value="Term Occurrences"/>
<parameter key="add_meta_information" value="true"/>
<parameter key="keep_text" value="true"/>
<parameter key="prune_method" value="none"/>
<parameter key="prune_below_percent" value="3.0"/>
<parameter key="prune_above_percent" value="30.0"/>
<parameter key="prune_below_rank" value="0.05"/>
<parameter key="prune_above_rank" value="0.95"/>
<parameter key="datamanagement" value="double_sparse_array"/>
<parameter key="data_management" value="auto"/>
<parameter key="select_attributes_and_weights" value="false"/>
<list key="specify_weights"/>
<process expanded="true">
<operator activated="true" class="text:transform_cases" compatibility="8.2.000" expanded="true" height="68" name="Transform Cases (2)" width="90" x="581" y="34">
<parameter key="transform_to" value="lower case"/>
</operator>
<connect from_port="document" to_op="Transform Cases (2)" to_port="document"/>
<connect from_op="Transform Cases (2)" from_port="document" to_port="document 1"/>
<portSpacing port="source_document" spacing="0"/>
<portSpacing port="sink_document 1" spacing="0"/>
<portSpacing port="sink_document 2" spacing="0"/>
</process>
</operator>
<operator activated="true" class="generate_aggregation" compatibility="9.5.001" expanded="true" height="82" name="Generate Aggregation (3)" width="90" x="782" y="289">
<parameter key="attribute_name" value="Häufigkeit der BP über alle Dokumente"/>
<parameter key="attribute_filter_type" value="all"/>
<parameter key="attribute" value="token_number"/>
<parameter key="attributes" value=""/>
<parameter key="use_except_expression" value="false"/>
<parameter key="value_type" value="attribute_value"/>
<parameter key="use_value_type_exception" value="false"/>
<parameter key="except_value_type" value="time"/>
<parameter key="block_type" value="attribute_block"/>
<parameter key="use_block_type_exception" value="false"/>
<parameter key="except_block_type" value="value_matrix_row_start"/>
<parameter key="invert_selection" value="false"/>
<parameter key="include_special_attributes" value="false"/>
<parameter key="aggregation_function" value="sum"/>
<parameter key="concatenation_separator" value="|"/>
<parameter key="keep_all" value="true"/>
<parameter key="ignore_missings" value="true"/>
<parameter key="ignore_missing_attributes" value="false"/>
</operator>
<connect from_op="Retrieve" from_port="output" to_op="Process Documents from Data (3)" to_port="example set"/>
<connect from_op="Process Documents from Data (3)" from_port="word list" to_op="Multiply (2)" to_port="input"/>
<connect from_op="Multiply (2)" from_port="output 1" to_op="Process Documents from Data" to_port="word list"/>
<connect from_op="Retrieve (2)" from_port="output" to_op="Process Documents from Data (2)" to_port="example set"/>
<connect from_op="Process Documents from Data (2)" from_port="example set" to_op="Set Role" to_port="example set input"/>
<connect from_op="Set Role" from_port="example set output" to_op="Multiply" to_port="input"/>
<connect from_op="Multiply" from_port="output 1" to_op="Process Documents from Data" to_port="example set"/>
<connect from_op="Process Documents from Data" from_port="example set" to_op="Generate Aggregation (3)" to_port="example set input"/>
<connect from_op="Generate Aggregation (3)" from_port="example set output" to_port="result 1"/>
<portSpacing port="source_input 1" spacing="0"/>
<portSpacing port="sink_result 1" spacing="0"/>
<portSpacing port="sink_result 2" spacing="0"/>
</process>
</operator>
</process>


