On a project for a recent client I needed to apply some common Natural Language Processing (NLP) techniques to surveys they had gathered, but one of the requirements for the project was that the source document had to remain in Word's .docx format and couldn't be exported to .txt. RapidMiner was the tool of choice for this engagement since it is graphical in nature and has a very usable library for text analysis, but what it doesn't have is an operator that specifically imports .docx files.
Microsoft Word files are basically zip files that contain an XML representation of the actual document. It stands to reason that if you can unzip the wrapper and get to the XML inside, you have a good chance of being able to read the document and do whatever you need in terms of analysis. RapidMiner has an operator for executing custom Python scripts (if you download the Python extension), so I chose to start there and see if it could handle those tasks.
Using Python in RapidMiner
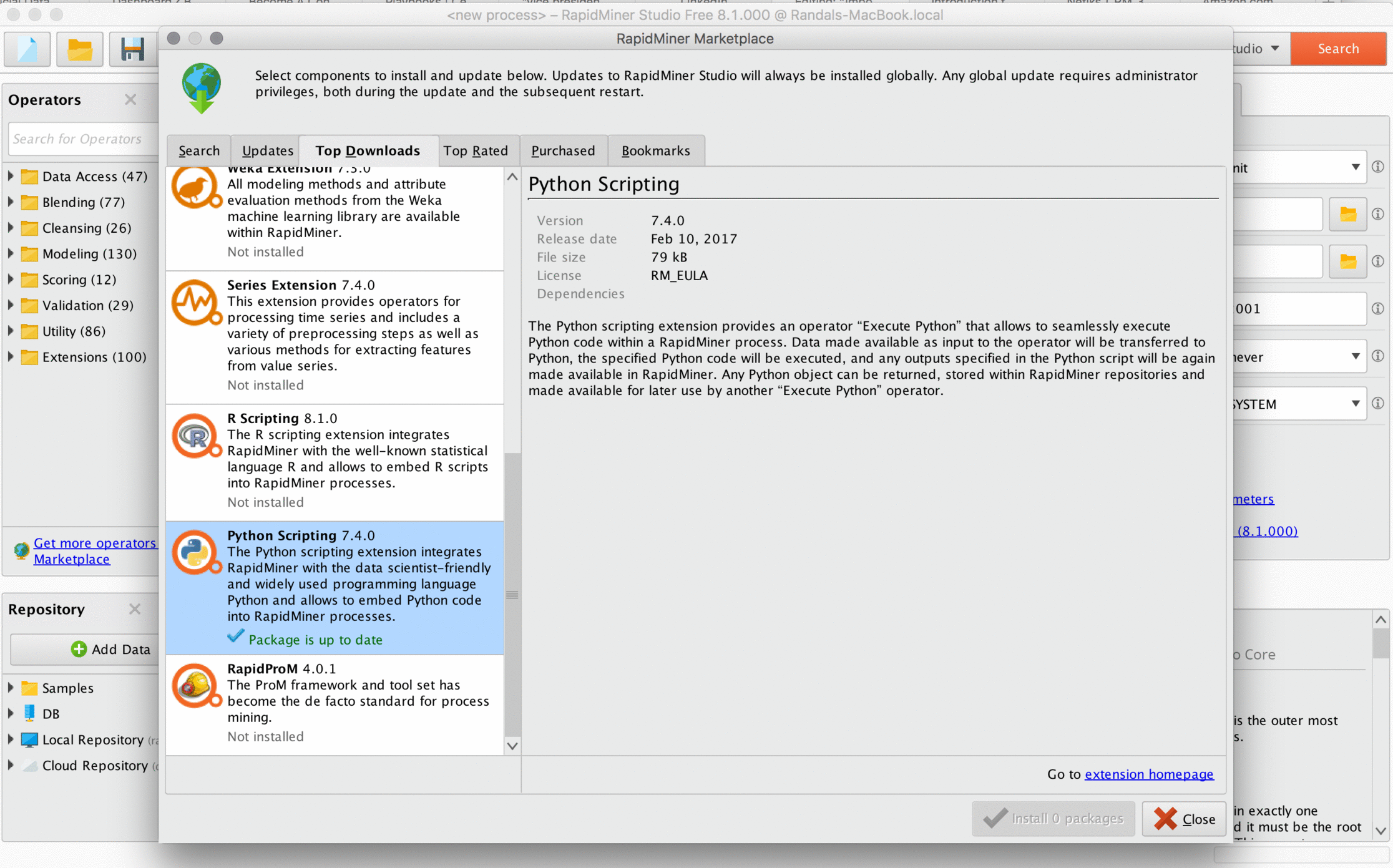
First we'll need to download the Python extension, which you can do by going to Extensions-->Marketplace in the menu at the top of the page. It's one of the most popular downloads, so just go to "Top Downloads," select it from the list, and click "Install Packages" at the bottom of the window. You'll need to restart RapidMiner afterwards for the extension's operators to become available.
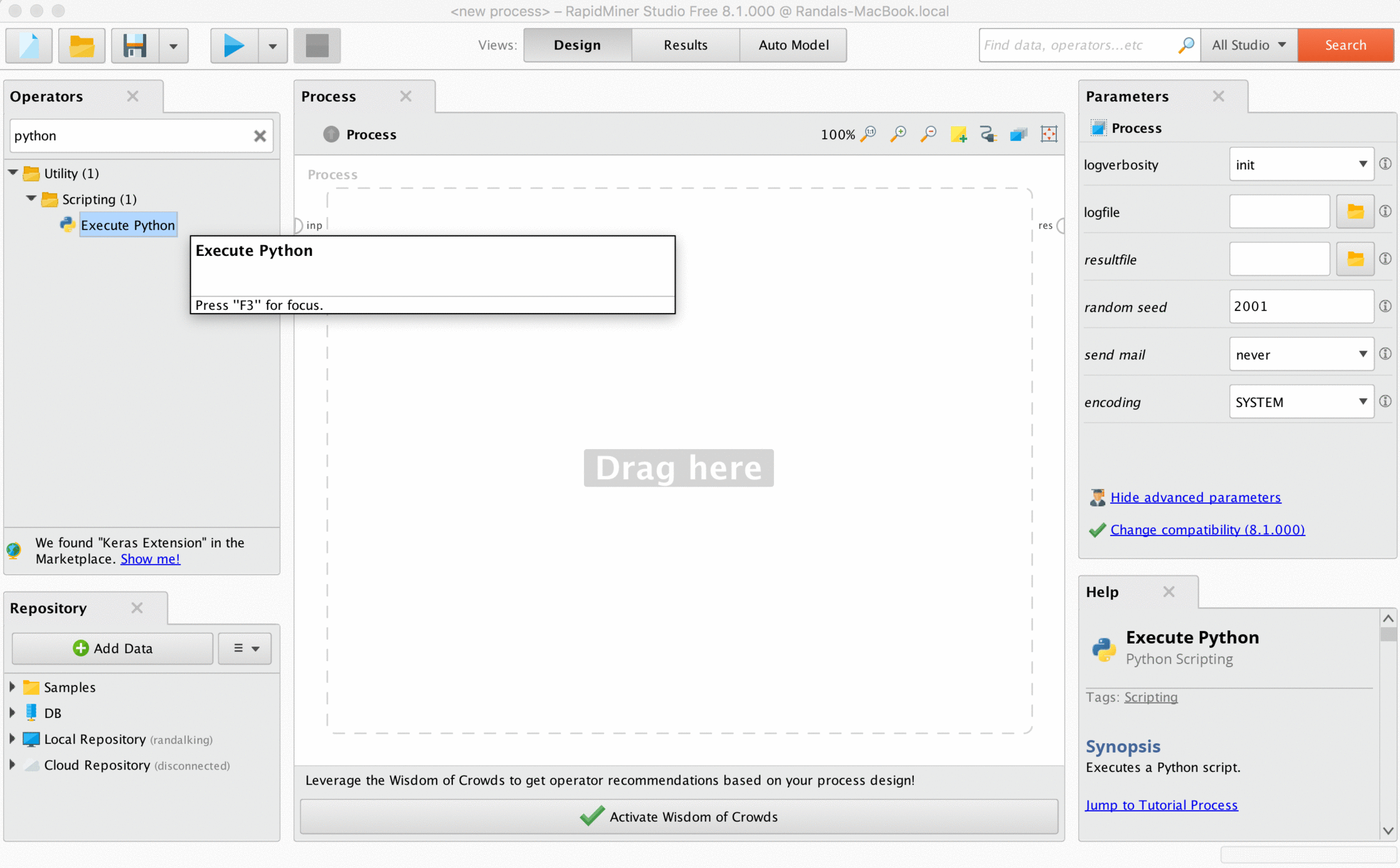
To use a custom Python script, search for the "Execute Python" operator and drag it onto the workflow. Double-click and you'll see the usual parameter editing box on the top right of the screen, which should contain a button labeled "Edit Text." This is where we'll enter the code.
The Code
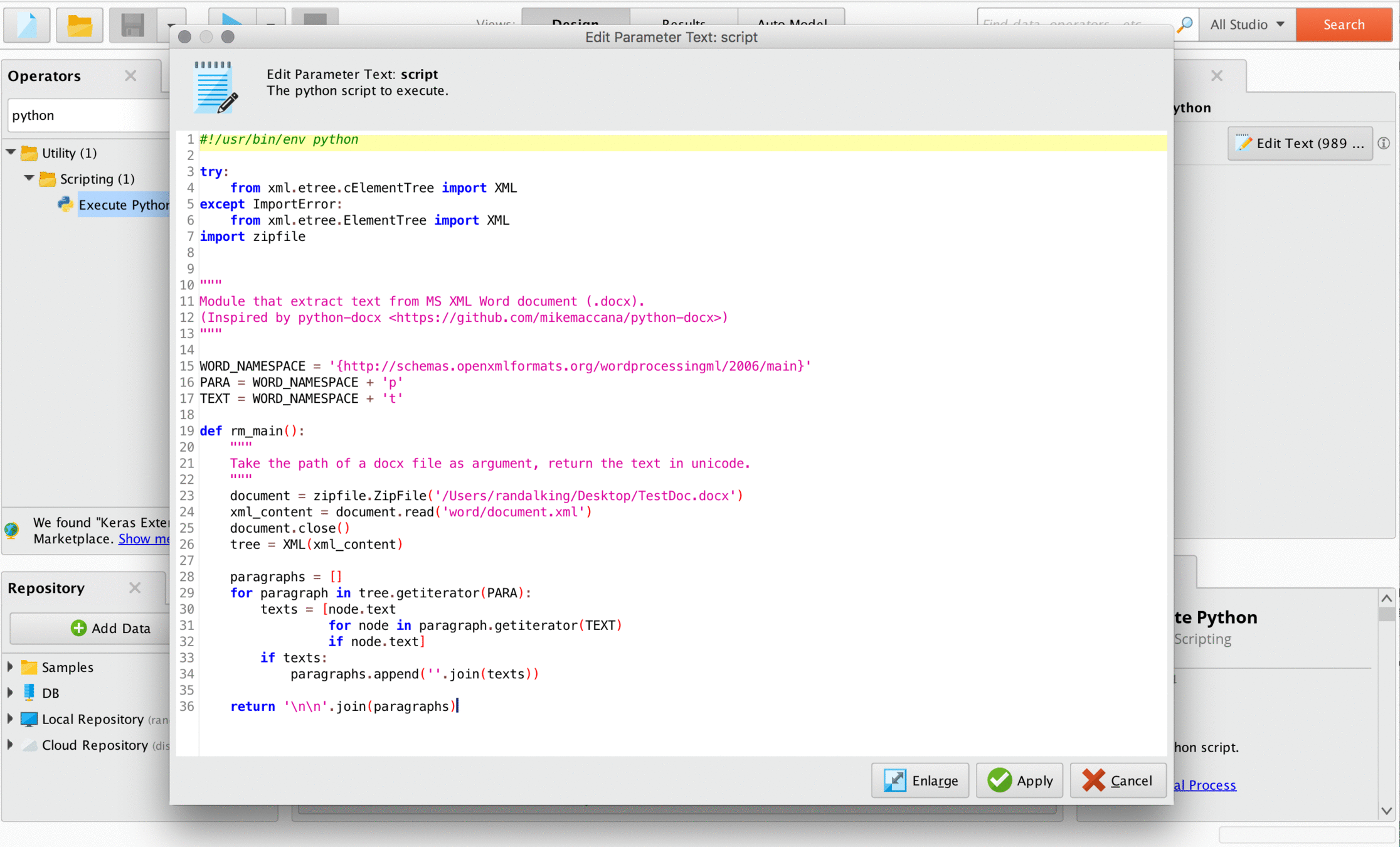
I try not to reinvent the wheel when coding, so I Googled the problem to see if someone had tackled it before me and someone definitely had. The code I used is below:
If you want to download it straight from Etienne's blog, just follow this link:
http://etienned.github.io/posts/extract-text-from-word-docx-simply/
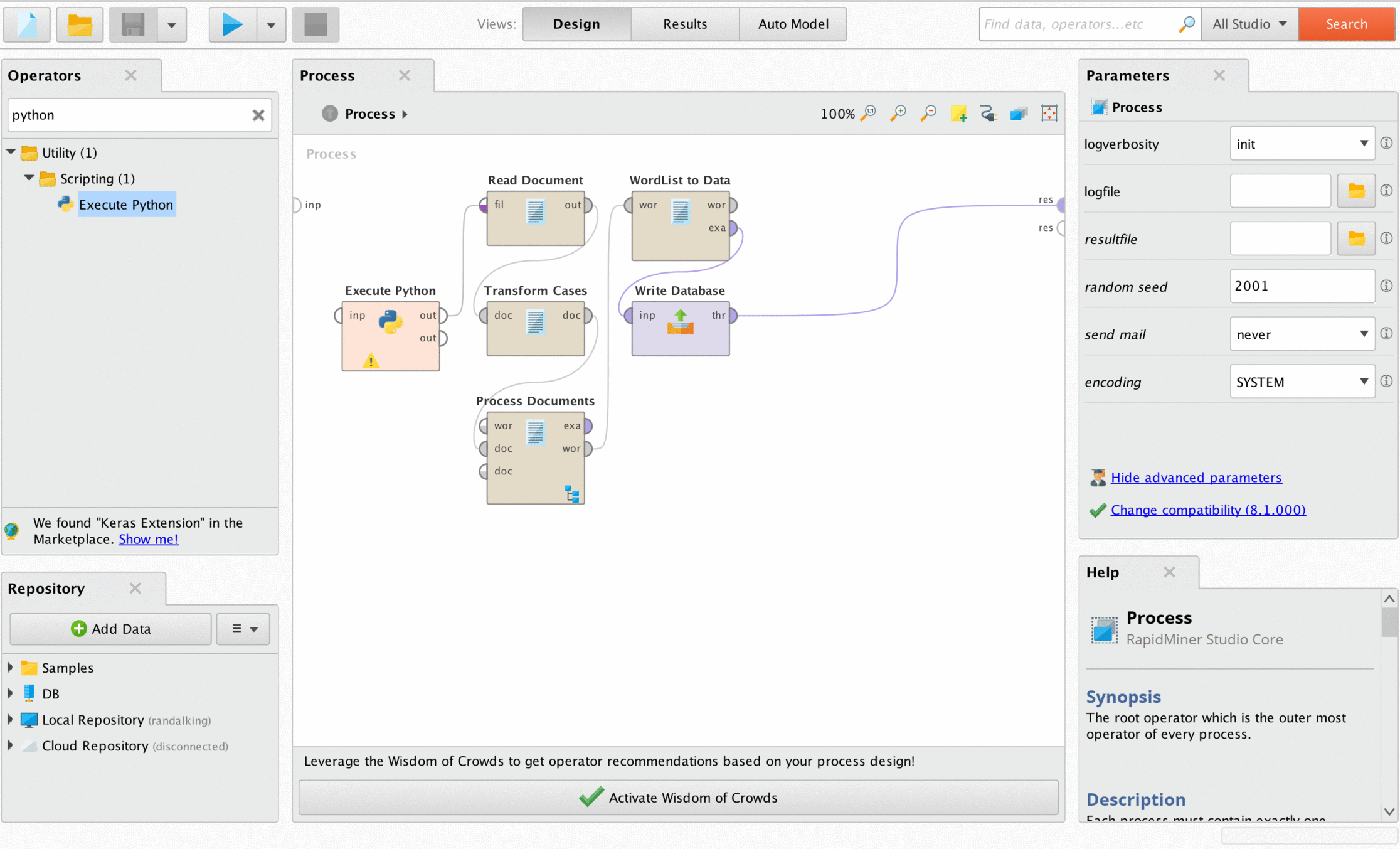
The initial workflow looked like this:
After using Etienne's code to unwrap the .docx file, it was easily readable by the "Read Document" operator. After that I transformed all words to lowercase, tokenized them, removed stop words, then converted the resulting word list to data and loaded it into a database for analysis. Simple.