Hello,
I am trying to classifiy documents (.txt) [sort into groups].
What I've dont so far:
Process Documents from Files (2 categories / classes) -> Tokenize -> Filter Stopwords ==> Learner ==> Apply Model (the document to classify comes from Read Document -> Process Documents (Tokenize, Filter) as you can see below:
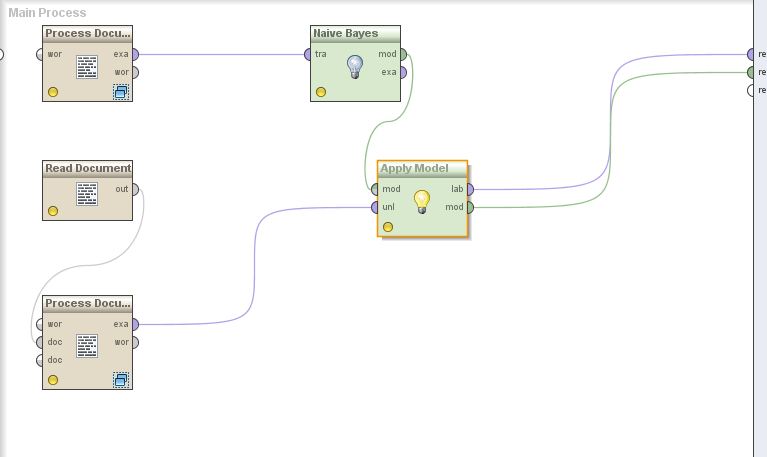
There are 6 documents for each class (Process Documents from Files) and a single document to classify.
Is this the right way to classify text / documents in Rapidminer ? I am asking because the results are confusing..just to make sure, I want Rapidminer to tell me "Your single .txt file belongs to class/category A or B".
Thanks in advanced!

