Hello forum
HS-1505: Register a Templex Function in HyperStudy
In this Tutorial , tep 5.19 the experimental result file is imported in *.xy format. But I have my experimental result file in *.csv form
Problem with importing this is values are not imported as X(frequency) and Y(frf) colums as seen in preview(img2). The actual plot of this values should be as indicated in red line in (compare.pdf)
Is there a way to convert csv to .xy format or import it directly in proper columnwise data.Is there way to chk what data is imported.
Regards
Pratik
<?xml version="1.0" encoding="UTF-8"?>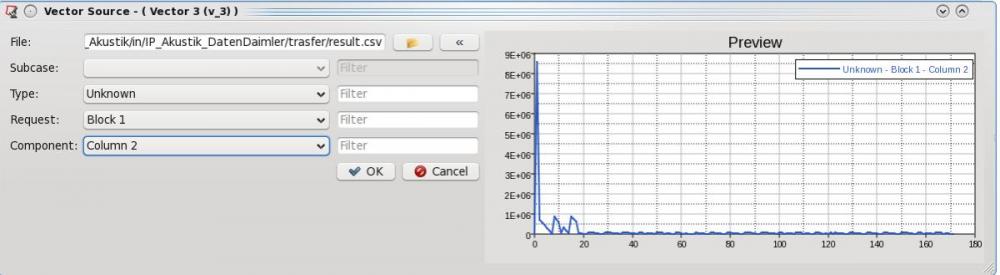
Unable to find an attachment - read this blog

