All data science projects require data, but many engineering problems have limited data. How much geometric data do you need to classify geometric shapes?
The most common question I get asked about Altair’s shapeAI technology is “How much data do I need?”. This is a very reasonable question, of course. Training a machine learning model to recognize a part requires data, and in many cases there is a finite amount of geometry available for training (and testing). While it is possible to work with limited data, predictive quality will improve as more data is provided for learning. This effect may be intuitive for some but, but to provide clarity to what this really means, it is instructive to walk through an example. In this article, we will investigate the effect of data size using the automobile geometries shown below.
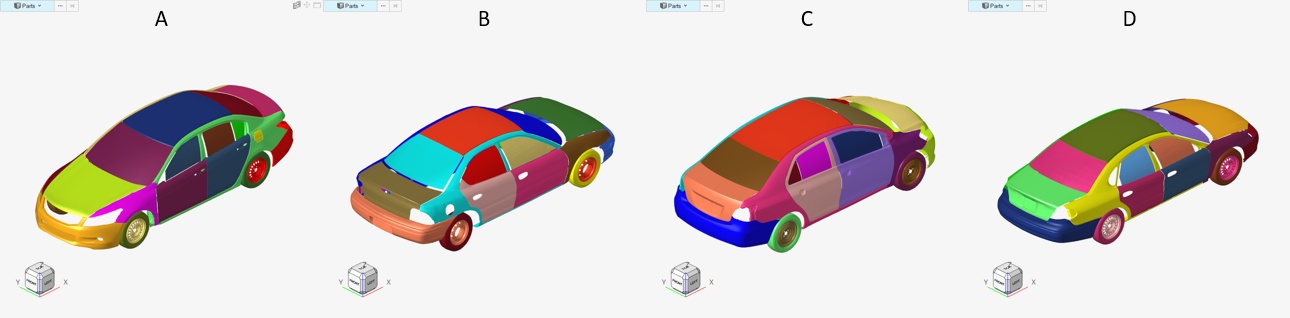
Here all the vehicles’ parts have been assigned to 5 categories: panel, tire, wheel, window, or other. For consistency in our assessments, vehicle D is used as a control test. This means the quality of our predictive models will always be scored against the ground truth of vehicle D. This allows us to test how well a machine learning model can learn from one set of data and generalize to another.
At the beginning of our investigation, we train 3 machine learning models, each on a single vehicle. This means one classifier trains only on vehicle A, another only on vehicle B, and the third only on vehicle C. Each model is then applied to geometries of vehicle D to test their predictions. The results are presented below, in both a tabular summary and a corresponding 3 visualization.

Numbers in the table assess the quality of the predictions for each class, ranging from 0 to 1 with a higher value being desirable. In the images, red indicates a predicted window, blue is panels, yellow is tires, green is wheels, and grey is the “other” class. In any of the three cases, the models learned to recognize tires and wheels clearly; this indicates that it is possible to learn from even a single vehicle. In contrast there are mixed results on panels and windows, and the model trained on vehicle C fails to correctly recognize any windows at all.
Knowing that more data typically helps, we next train 3 more machine learning models but this time each training set consists of two vehicles worth of data. The means one classifier trains on vehicles A and B, another on A and C, and the third on B and C. When applied to vehicle D, the results are shown here.

Yet again, there are quite a few misidentified parts, but the overall learning has improved. The tires and wheels maintain their accuracy, yet more importantly the models perform better on windows.
Only using the geometries from vehicles A, B and, C, we train a single machine learning model. The prediction quality on vehicle D is shown below.

Unmistakable in this improved performance, we can see the continuing correlation between the amount of data and model predictive quality. At first glance, this result looks similar to the previous result using only B and C, but a there is clear improvement in panels and the window class also shows is general improvement compared to the previous attempts.
Despite its questionable value, we can examine predictive performance when all four vehicles are used for training. This has questionable value because the controlled testing geometry (vehicle D) is now part of the test set, but regardless, the prediction quality is presented here

Predictably, the model performance is greatly improved when it is applied to a previously seen data. It is worth noting that even in this case, the model doesn’t have perfect recall as some panels are misidentified, as can be seen on the rear bumper.
Generalizing part classifiers with Altair’s shapeAI are possible provided that sufficient data is available during model training to improve predictive quality. The example in this article shows while even few pieces of geometric data can produce learning models, their quality does improve quickly as more data is included. More specifically, accurate identification of known geometries is possible with very limited training data, but more data is required to generalize satisfactorily to new unseen geometries. With enough data, shapeAI can learn to recognize parts, and empower artificial intelligence to augment and enhance the model build process via automations.
