I quite often get asked how to do a join using multiple variables as keys within Knowledge Studio/Seeker. We had originally used a third party's algorithm to do this for us, but recently removed it due to licensing changes. It on the roadmap to replace, but in the meantime, here's a couple of alternatives.
Multi-key Join using Knowledge Studio Native:
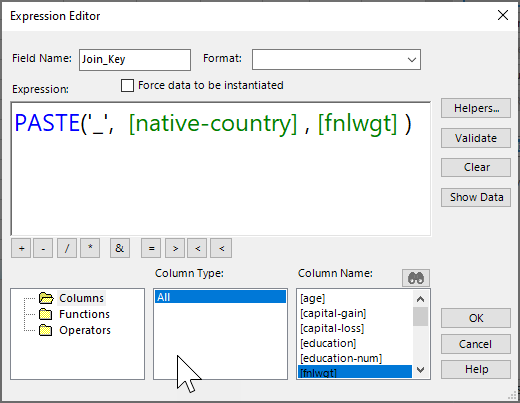
Currently, the easiest way to do it is to do it over two steps, firstly using the Variable Transformation node to concatenate or paste fields:
Here's an example using paste, but you could also use concat.

Then use this 'join_key' as the join key for the merge and complete the rest of the wizard.

Merges Using Pandas
Some users might find this a little tedious and may prefer to use a code node instead. My preference is to use Python, but it does depend on where you're planning on deploying to (if you are planning on deploying it).
To do in Python you need to attach a generic code node to the datasets. Here I've performed some aggregations to the census node and attached them to the python node.
This has created the conversion code from Angoss to Python (and back).
Census1DF = AngossUtilities.AngossToDataframe(directory, "Census1")
Converts the Census2 dataset to a dataframe (a python data set) called Census2DF. You can type this into the python console if you want to play around with it.
The '#'s are signifying a comment – so you remove some of them a bit later.
You should already have the pandas library available (pandas is a library for storing and manipulating data in memory). So first you need to import it for use:
import pandas as pd
To perform a merge using pandas use the following command:
<output_dataset>=pd.merge(<input dataset1>, <input_dataset2> , on=['<key1>','<key2>',…], how='<join type>')
For example, to perform an 'inner' join on 'CensusDF' and 'Census2_AggregatedDF' using the keys 'sex' and 'age'. (Beware that this is case-sensitive!)
CensusMerge=pd.merge(Census2DF, Census2_AggregatedDF, on=['sex','age'], how='inner')
Then you can output this to an Angoss dataset:
AngossUtilities.DataframeToAngoss(directory, CensusMerge, "CensusRES")
Your final node will look something like this:
I've made a generic form of this if you prefer to just copy and paste.
#------------------------------------------PASTE THE BELOW IN -----------------------------------------
# MODIFY THE FOLLOWING ROWS:
# Input file 1 name - usually the same as the "Sources" box on the right e.g.
input_file_1="census"
# Input file 2 name e.g.
input_file_2="census2"
# Type of join - one of inner outer full left right
join_type='inner'
#keys=<comma separated list of keys> e.g.
keys="age","gender"
# The name of the output file - this must be added to the "Targets" box on the right
output_filename="census_merged"
# ---------------------------------------------------------------------------------------------------------------
import pandas as pd
ds1DF = AngossUtilities.AngossToDataframe(directory, input_file_1)
ds2DF = AngossUtilities.AngossToDataframe(directory, input_file_2)
ds_join=pd.merge(ds1DF,ds2DF,on=keys, how=join_type)
AngossUtilities.DataframeToAngoss(directory, ds_join, output_filename)
Hope this helps!