Hey everyone,
I'm currently working on my Master's thesis, which focuses on improving Process Mining visualizations to enhance user interaction within Moodle, a Learning Management System.
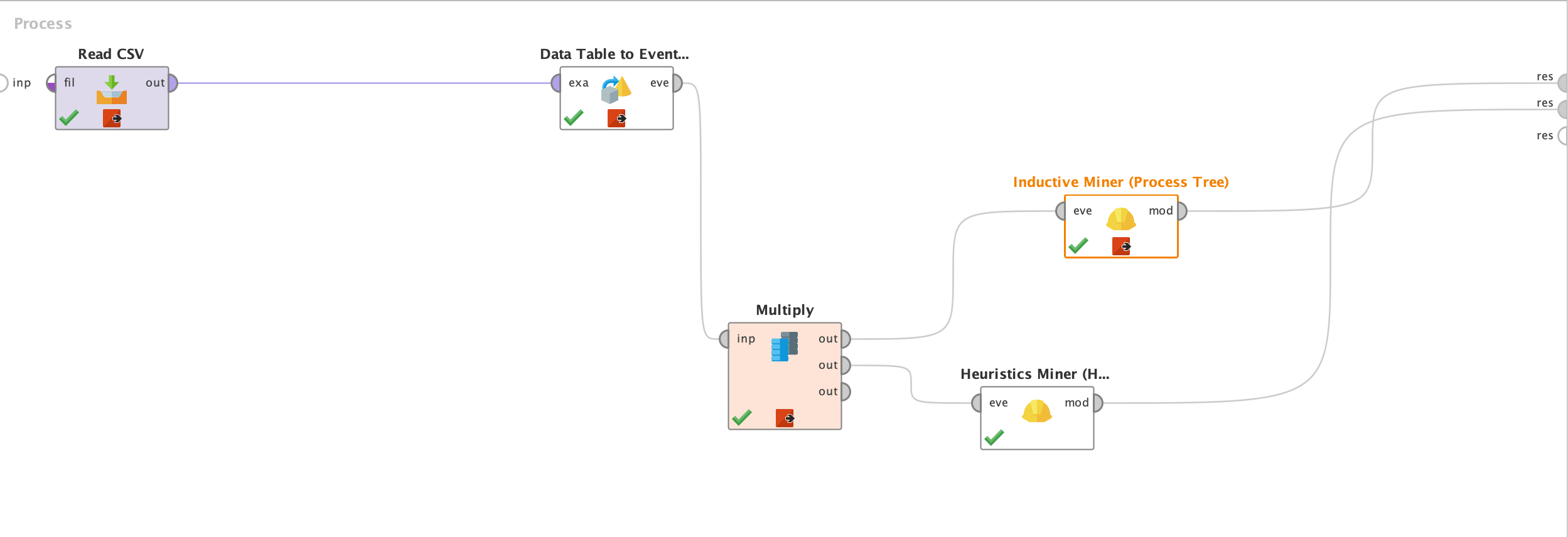
I'm using RapidMiner for this project and have been experimenting with the following operators:

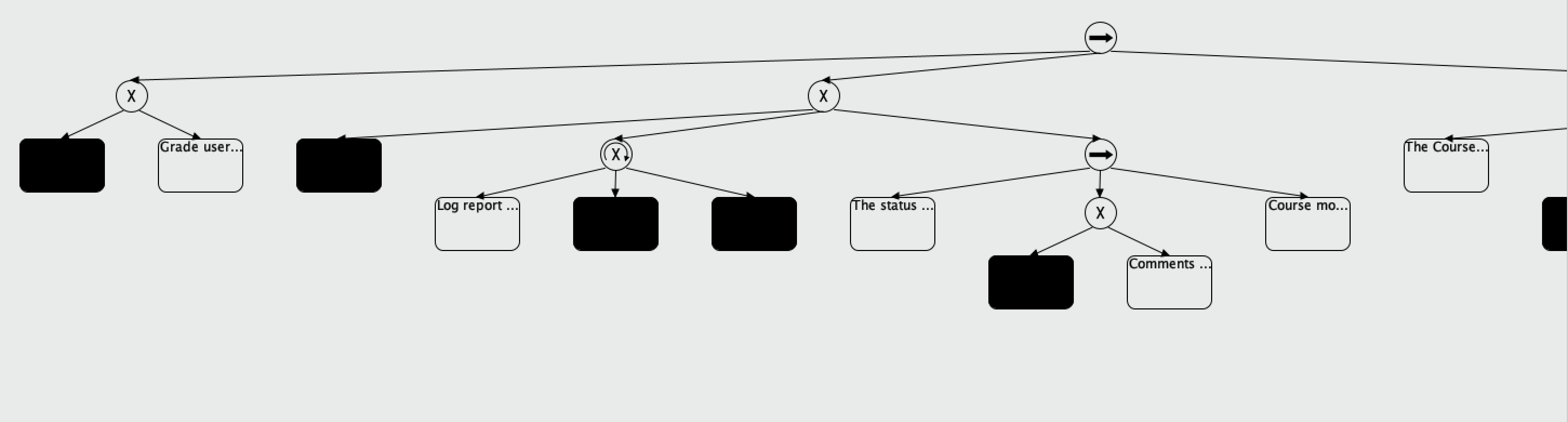
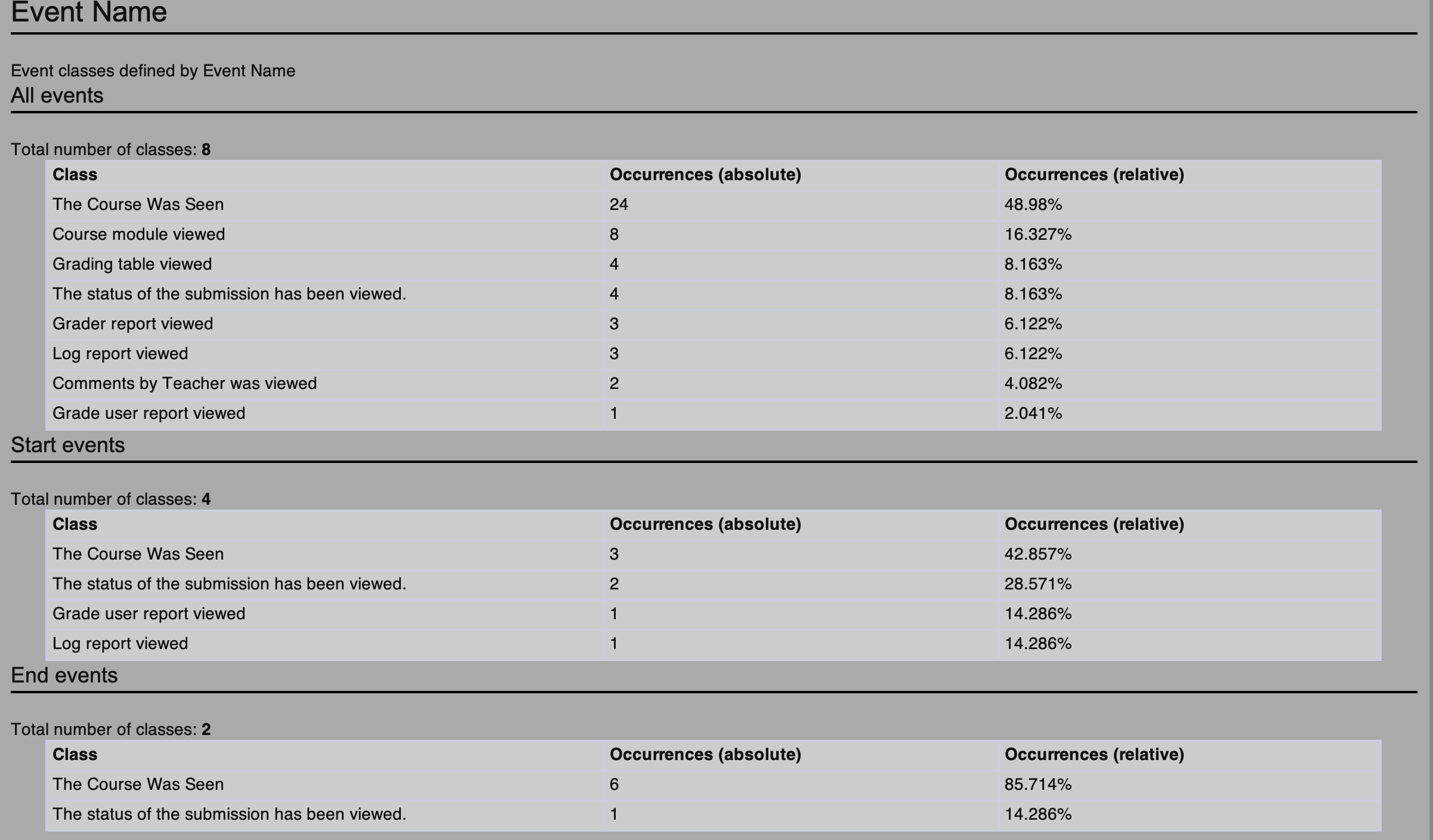
Attached are a) the visualizations I've generated so far and b) a sample of the dataset, c) the process .rmp file. However, I've have a few questions that I'd greatly appreciate some help with:
1) Is data preprocessing essential for achieving effective visualizations, even if my primary goal is to just visualise the process?
2) When working with event logs, do I need to specifically select examples that have a clear beginning and end point for process mining?
3) While using the "Data table to event logs" operator, should I include the date attribute?
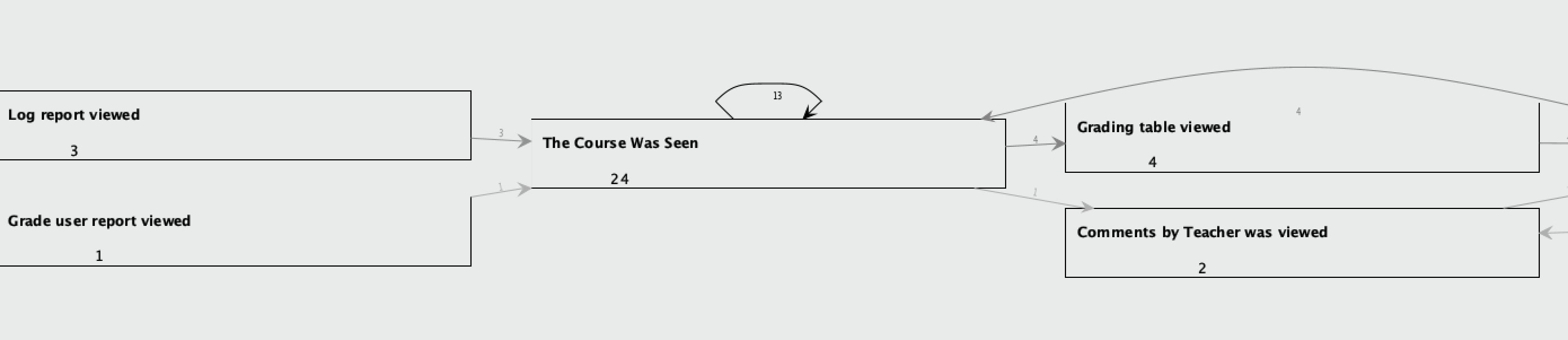
4) In the Heuristic Miner output (see attached), there are numbers displayed between the event classes. Could someone explain what these numbers represent? Is it an indication of participant frequency for a specific path, where a higher number signifies a more frequently taken path?
Thank you in advance for any insights or help you can provide!