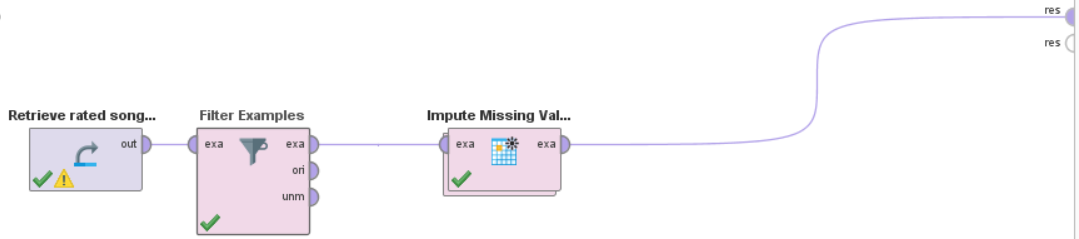
Hello all,
I have a dataset with about 3000 records of rated songs. About half are rated, the other half is not. I'm trying to build a model that predicts the empty ratings based on what users rated. I have done the following:
My question is, is this correct? Do I need to make adjustments to make it more correct? Because when I for example already change the k I get different values. And another question: how do I show only the values that have been predicted instead of a full overview, including the already filled in values.
Thanks in advance!